 请求处理中...
请求处理中...
请求处理中...
请求处理中...
本文将由一品威客小编为您介绍关于Apache IoTDB如何作为一款为海量工业物联网而生的时序数据库,解决企业数据管理的世纪难题。你是不是也正在为工厂里成千上万的传感器数据、飙升的存储成本和查询慢到抓狂而“发懵”?别慌,这位来自Apache基金会的顶级“开源选手”,可能就是你的救星,希望能够帮助大家。
想象一下,一个大型工厂,每秒都有成千上万的传感器在产生数据——温度、压力、转速、震动……这些数据不仅海量,还源源不断。用传统数据库(比如MySQL)来存?分分钟撑爆,查询慢得像蜗牛,成本高到离谱,对吧?这感觉简直就是在打乱仗!
但偏偏,工业智能化又离不开这些数据。怎么办?死磕老技术肯定不行。今天,小编就带你认识一位专治各种“工业数据不服”的天选之子——Apache IoTDB。它到底有啥“狠活”,能成为Apache基金会的顶级项目?下面这5点,给你讲得明明白白!
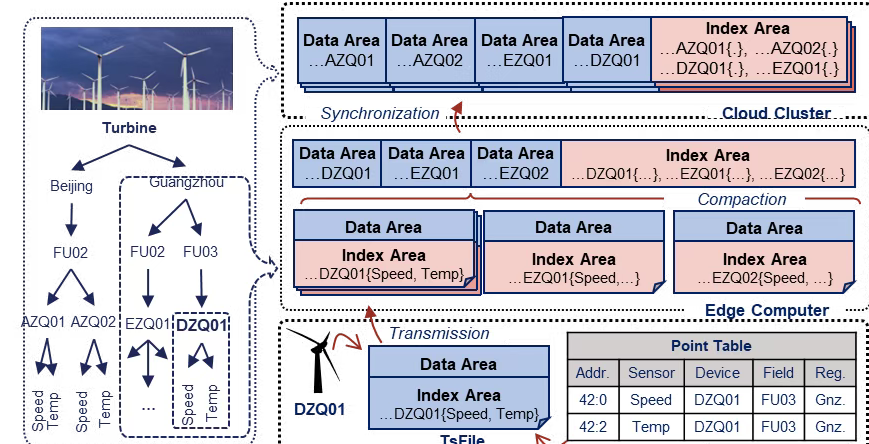
狠活一:专为“时序数据”而生,原生分布式架构超能打
首先,你得知道,IoTDB从根子上就不是普通数据库。它是时序数据库,专门为处理带时间戳的数据而设计的。
举个例子: “2023-10-27 10:00:00,设备A,温度=25.3℃”这就是一条典型的时序数据。IoTDB存储这类数据,效率比通用数据库高N个级别!
核心优势: 它采用原生分布式架构,意思是天生就为分布式部署而设计。数据多了?简单,加机器就行!轻松横向扩展,“海量”这个词在它面前就是个弟弟,完全不用担心架构瓶颈。
狠活二:“超高压缩比”,存储成本直接打骨折
工业数据最烦人的一点就是“占地方”。原始存储?那得花多少奶茶钱啊!
怎么做? IoTDB内置了超强的专用压缩算法。对于时序数据,压缩比经常能达到10:1甚至更高!
省钱版解读: 本来要买10T的硬盘,现在可能1T就搞定了。这省下的可是真金白银的硬件和运维成本,老板看了都直呼内行。
狠活三:“边-云协同”,一套架构打通任督二脉
工业场景经常是边缘端(工厂本地)和云端都要处理数据。换别的技术,两边系统可能都不一样,协作起来很麻烦。
IoTDB的解决方案: 它直接提供了 “边-云协同” 一套架构。在边缘端,它可以作为一个轻量级的数据库运行;处理完的数据,可以高效地同步到云上的IoTDB集群。
避坑指南: 这避免了数据孤岛,实现了“一套技术栈,覆盖全场景”,管理和开发效率飙升,再也不用两边“打乱仗”了。
狠活四:查询快如闪电,告别“慢查询”噩梦
存进去不是目的,快速分析出来才是关键。面对亿级数据点,传统数据库查询可能直接“装死”。
核心优势: IoTDB针对时间序列的查询做了极致优化。比如,你要查询“一号车间A生产线过去一周每分钟的平均温度”,这种聚合查询对它来说就是小菜一碟。
效果: 查询速度比通用数据库快几十到上百倍都是常态。让实时监控和分析成为可能,而不是一个美好的愿望。
狠活五:生态无缝集成,告别“适配地狱”
一个数据库再好,如果跟现有系统玩不到一块去,也是白搭。
IoTDB怎么做? 它深谙此道,与Apache生态圈的各种大佬(如Spark, Flink, Hadoop)无缝集成。同时,也完美支持Grafana这种流行的可视化工具,以及MQTT等工业协议。
小编划重点: 这意味着你可以用现有的、熟悉的技术栈,平滑地接入和使用IoTDB,学习成本低,集成难度小,“新手友好” 程度满分!
总结一下:
面对工业物联网海量时序数据的挑战,Apache IoTDB凭借其原生分布式架构、超高压缩比、边-云协同、高性能查询和强大的生态集成这五大“狠活”,提供了一个非常能打的开源解决方案。它不是什么“玄学”,而是经过Apache基金会验证的、实实在在的顶尖技术。
下一步做什么?
别光说“牛逼”就完了!这么好的开源项目(免费,懂我意思吧?),还不赶紧去了解一下?去官网下个社区版试试,又不要钱!说不定,你团队头疼已久的数据难题,一杯奶茶钱的功夫就能找到新思路了!

交易额: 3412.16万元
企业 |山东省 |临沂市 |临沂市
交易额: 1081.25万元
企业 |山东省 |青岛市 |城阳区
交易额: 427.32万元
企业 |山东省 |济南市 |历下区
交易额: 167.8万元
企业 |浙江省 |温州市 |瓯海区
成为一品威客服务商,百万订单等您来有奖注册中

价格是多少?怎样找到合适的人才?
¥1000 已有0人投标
¥100 已有1人投标
¥10000 已有0人投标
¥50000 已有4人投标
¥20000 已有2人投标
¥10000 已有6人投标
¥5000 已有5人投标
¥10000 已有3人投标








 企业QQ
企业QQ
 智能客服
智能客服





