您的企业是否正面临数据孤岛、分析滞后、决策失准的困境?搭建一套实时的数据采集和分析系统,正是破解这些难题、驱动业务增长的关键引擎。本文将以清晰的“金字塔”结构,直指核心,为您系统化拆解从零搭建实时数据系统的五大关键步骤:从奠定基石的设计数据库系统,到规划数据动脉的系统架构设计,再到精准选型与部署数据采集分析工具,最终实现数据处理与价值呈现。无论您是需要软件开发定制设计数据库系统采集分析工具管理咨询服务,还是希望自主技术攻关,本文都将为您提供一份清晰的行动路线图,帮助企业构建从数据到洞察的核心竞争力。

第一步:需求蓝图的精准描绘与数据源盘点在编写第一行代码或选择任何一个工具之前,必须明确系统的目标和边界。
明确业务目标:系统是为了实现实时大屏监控、精准用户画像,还是实时风险预警?不同的目标决定了不同的技术架构和资源投入。
盘点数据源:全面梳理企业内外的数据来源,包括业务数据库(MySQL/Oracle)、服务器日志、前端/App用户行为埋点、第三方API数据等。了解数据的格式、量和产生频率。
定义关键指标:与业务部门共同确定需要实时监控和分析的核心指标,如实时交易额、活跃用户数、系统错误率等。
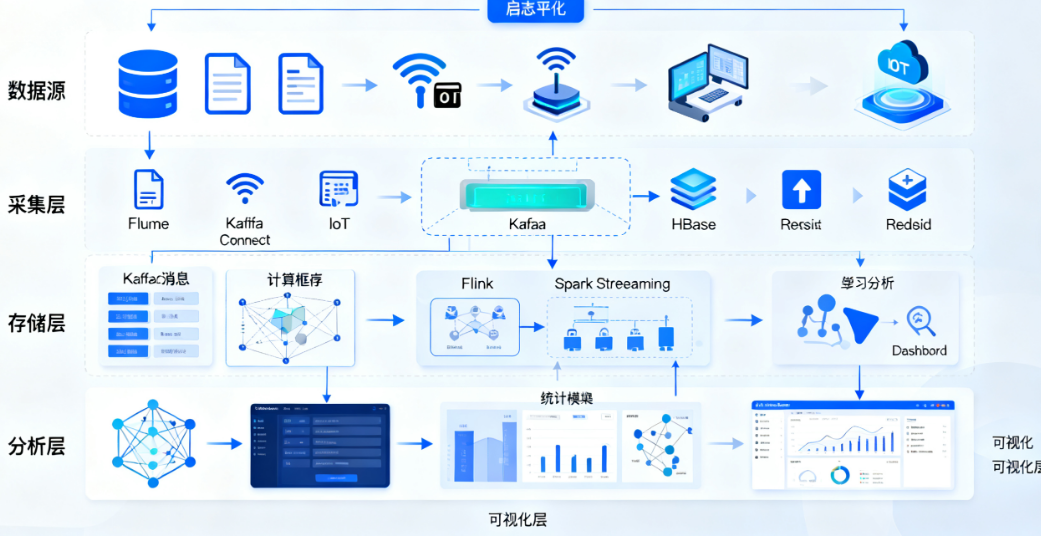
第二步:系统架构的顶层设计——构建数据高速公路一个稳健的系统架构设计是确保数据能够高效、稳定流动的“骨架”。现代实时系统通常采用流批一体的思想。
数据流向规划:设计从数据采集、传输、处理到存储和应用的全链路流程。
核心技术选型:
消息队列:引入Kafka或RocketMQ作为数据的“高速公路”和“缓冲池”,解耦数据生产与消费,应对流量高峰。
流处理引擎:采用Flink或Spark Streaming作为“实时计算大脑”,负责在数据流动过程中进行实时聚合、计算和规则判断。
数据服务层:将处理后的结果通过API接口提供给前端应用、BI工具或其他业务系统。
第三步:数据库系统的精心设计与选型数据最终的归宿和查询性能,直接取决于如何设计数据库系统。这里需要根据数据的使用场景进行分层和选型。
分层架构:
ODS层:存储原始数据,通常选用高吞吐的Kafka或HBase。
DWD/DWS层:存储清洗和聚合后的明细与汇总数据,为分析查询服务。可选用列式存储的ClickHouse、云数据仓库或Hive。
选型关键点:需平衡数据的写入性能、查询速度、成本以及运维复杂度。(想深入了解?推荐阅读:
《物联网数据库选型有哪些关键点?》)
第四步:数据采集分析工具的集成与部署这是将数据从源头引入系统的“毛细血管”网络。选择合适的数据采集分析工具至关重要。
前端埋点:集成SDK(如 Sensors Data、GrowingIO)到App和网站,自动化采集用户点击、浏览、停留等行为数据。
后端数据同步:使用Canal监听数据库binlog,或使用DataX、Logstash等工具进行批量与增量同步,将业务数据实时接入消息队列。
工具整合:确保这些工具能与中台的流处理引擎和底层数据库顺畅对接,形成完整的数据闭环。
第五步:实时处理、可视化与应用落地这是系统产生价值的最终环节,通过
数据采集分析工具的处理和展示能力,将数据转化为洞察和行动。
实时计算与告警:在流处理引擎中编写业务逻辑,实现实时指标计算。并设定阈值,一旦触发,立即通过短信、钉钉等方式告警。
数据可视化:将实时计算结果输出到Grafana、DataV等大屏工具,或集成到BI平台中,为决策者提供直观的数据视图。
数据服务化:通过API将实时数据(如实时用户画像)反哺给业务系统,用于个性化推荐、精准营销等场景,真正实现数据驱动。(扩展学习:
《数据库应用系统开发:提升企业数据管理效能》)
搭建一套实时的数据采集和分析系统,是一项系统工程,它要求我们具备前瞻性的系统架构设计能力,懂得如何科学地设计数据库系统,并能够熟练地集成与运用各类
数据采集分析工具。成功落地这样一套系统,不仅能极大提升企业的运营效率,更能构筑起难以逾越的数据护城河。如果您在项目规划或实施中需要专业的软件开发定制设计数据库系统采集分析工具管理咨询服务,我们随时准备为您提供助力。
 请求处理中...
请求处理中...










 企业QQ
企业QQ
 智能客服
智能客服





