
引言:
想为Telegram频道打造专属的数据监控或营销工具,却屡屡碰壁?
开发配套Telegram软件时,高频遭遇的API限制、
数据采集延迟、实时搜索不准等难题,常让项目进度停滞,运营效率不增反降。本文直面三大核心痛点:突破官方接口封锁、构建毫秒级搜索、实现稳定实时预警。我们为您拆解问题根源,并提供经过验证的分布式架构、流处理及智能调度等实战解决方案,助您将技术障碍转化为竞争优势。立即阅读,解锁高效稳定的Telegram生态开发之道。本文将汇总开发此类“
配套Telegram软件”时最常遇到的3大技术难题,并提供经过验证的解决方案,帮助开发者和站长少走弯路。
问题一:数据采集效率低下,如何突破Telegram API的限制与风控?问题描述: 开发“配套Telegram软件”的第一步——数据采集,就极易碰壁。直接调用API可能面临速率限制、请求被封,甚至账号被禁的风险,导致数据不完整、更新不及时。
根源分析: Telegram官方为保护其服务器和用户体验,对
机器人API和MTProto协议调用有严格的频率和并发限制。粗暴的抓取行为会触发风控机制。
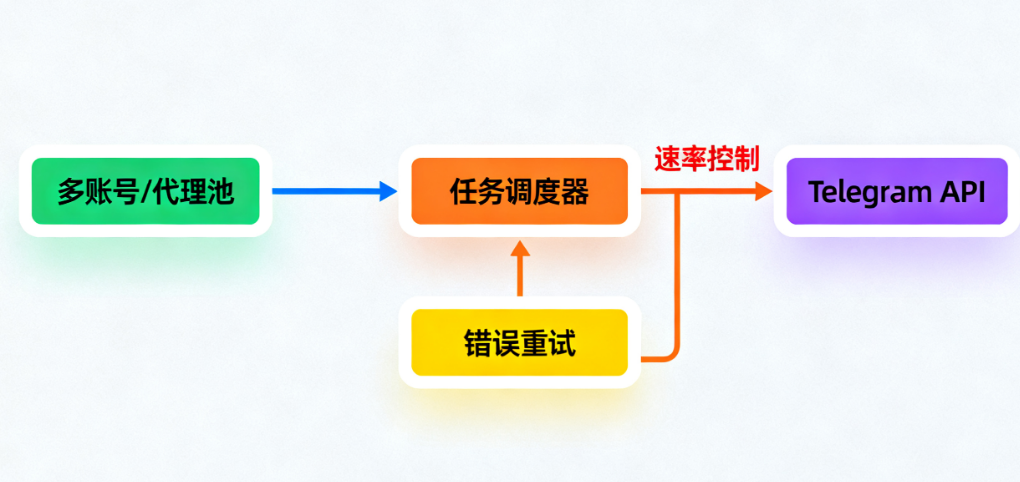
解决方案:采用分布式、多账号轮询架构: 不要依赖单一账号或IP。
设计一个账号池和代理IP池,将抓取任务均匀、分散地分配,模拟人类操作间隔,这是构建稳定“配套Telegram软件”数据层的基石。
实现增量更新与智能调度: 并非每次都需要全量抓取。记录最后一条消息ID,只拉取新消息。为不同活跃度的频道设置不同的抓取频率(如热门频道每5分钟,冷门频道每小时),优先保证核心数据的实时性。
严格遵守规则并使用官方推荐方式: 仔细阅读Telegram Bot API文档,使用getUpdates轮询或Webhook时,合理设置limit和timeout参数。对于大规模数据需求,考虑通过Telegram的官方途径(如申请开发者权限)获取更合规的接入方式。
问题二:海量非结构化数据处理难,如何实现精准、快速的搜索?问题描述: 采集到的消息是文本、图片、视频、链接的混合体。如何从中快速找到站长关心的“某一关键词的所有讨论”或“含有某类文件的频道”?原生Telegram搜索对此无能为力。
根源分析: 数据格式多样、文本质量参差不齐(含有大量表情符、口语化缩写)、语言多样,给建立高效索引和相关性排序带来巨大挑战。
解决方案:构建ELK技术栈核心: 使用Elasticsearch作为搜索与推荐引擎的核心。利用其强大的全文检索、分词和聚合能力,对清洗后的文本、元数据(频道名、作者、时间)建立倒排索引。
设计分层数据处理流水线:清洗层: 过滤广告、垃圾信息,提取纯文本。
解析层: 识别实体(@用户名、#话题标签、URL),将媒体文件通过OCR或语音转文本进行内容提取。
索引层: 定制分词器(尤其处理好中文混合外文),为不同字段(如标题、内容、标签)设置不同的权重,优化BM25相关性算法。
引入缓存与预计算: 对热门搜索词、频道分析结果使用Redis进行缓存。对于复杂的聚合分析(如“本周各频道互动趋势”),可在后台定时预计算好结果,极大提升前端查询速度。

问题三:实时监控与告警不稳定,如何保证系统的即时性与可靠性?
问题描述: 站长需要第一时间知道竞品发布了新活动或特定关键词被提及。但自建的监控系统常常延迟高、漏报或误报,变成“马后炮”,失去了“配套Telegram软件”的预警价值。
根源分析: 简单的定时轮询无法保证实时性;业务逻辑耦合过紧,一处出错可能导致整个监控链断裂;缺乏有效的失败重试和状态告警机制。
解决方案:采用流处理架构处理实时数据流: 引入Apache Kafka或Pulsar作为消息队列。数据采集模块一旦获取到新消息,立即作为事件发布到消息队列。监控服务作为消费者实时处理,实现秒级延迟。这是实现实时处理系统的关键。
实现事件驱动的告警引擎: 告警规则与核心业务逻辑解耦。告警引擎监听处理后的数据流,根据用户预设的规则(如“A频道5分钟内新增粉丝大于1000”)独立判断并触发通知。支持多种通知渠道(Telegram Bot、邮件、Webhook)。
建立完善的运维监控与自愈机制: 为“配套Telegram软件”自身设立监控。追踪数据管道的健康度(如Kafka lag)、服务心跳、API调用成功率。一旦发现异常,自动触发告警(通知运维人员)或尝试自愈(如重启失败的任务)。
总结:
回顾核心: 开发一款强大的
“配套Telegram软件”,成功关键在于妥善解决数据采集、处理与实时响应这三个环环相扣的问题。
技术提炼: 本质上需要结合分布式系统设计(应对API限制)、大数据处理能力(实现精准搜索)和实时计算架构(保障监控即时性)。
价值升华: 攻克这些技术难点后,这款软件将从简单的工具升级为站长的“战略决策系统”,真正在竞品分析、趋势发现和用户洞察上提供不可替代的价值,凸显其技术可行性与商业潜力。
行动号召: 鼓励读者从一个小而核心的功能(如单一关键词监控)开始迭代开发,逐步完善,最终打造出属于自己的专业级运营利器。
资料搜集与内容填充:针对“问题一”的深度分析【问题一:数据采集效率低下,如何突破Telegram API的限制与风控?】 进行详细的原因和解决方法整理。
造成该问题的常见原因:
官方硬性限制:Bot API频率限制: 对getUpdates、sendMessage等方法有明确的每秒、每分钟、每日调用次数上限。例如,默认情况下,每秒来自同一机器人到同一聊天室的消息有限。
MTProto连接限制: 用户账号或机器人通过MTProto连接时,Telegram服务器对连接数、请求并发数和频率有严格管制,远超限制会导致FLOOD_WAIT错误甚至会话断开。
单一访问模式:使用单一账号/IP: 所有请求都来自同一个Telegram账号和服务器IP地址,行为模式单一且密集,极易被服务器识别为机器人恶意爬取,从而触发风控。
抓取策略粗暴:全量轮询,不分优先级: 无论频道是否活跃,都按相同的高频率进行完整历史记录拉取,产生大量无效请求,白白消耗请求配额。
错误处理不当: 遇到FLOOD_WAIT等错误时,没有采用指数退避等策略进行重试,而是持续重试,导致问题恶化。
3种实用的解决方法:
方法一:构建分布式、智能调度的采集集群
做法:准备多个Telegram机器人令牌(Bot Token)或已登录的用户账号(通过MTProto),形成一个“账号池”。
使用多个代理服务器(Residential Proxy更佳)形成一个“IP池”。
开发一个中央调度器,将需要监控的频道列表动态分配给池中的不同账号和IP。
为每个账号设置合理的请求间隔(如每秒1-2次请求),并在调度逻辑中避免对同一目标短时间内发起过多请求。
优点: 将负载均匀分散,极大降低单个账号/IP触发限制的风险,采集稳定性和规模得以提升。
方法二:实施增量抓取与差异化频率策略
做法:为每个监控的频道/群组保存最新已处理消息的message_id或date。
每次抓取时,仅请求比该ID或时间更新的消息(如使用offset参数)。
根据频道活跃度(如过去24小时消息量)将其分为高、中、低三级。
配置不同的抓取间隔:高活跃度频道每1-2分钟抓取一次,中活跃度每10分钟,低活跃度每小时或每天。
优点: 显著减少冗余请求,将宝贵的请求配额集中在更新频繁的源上,提高数据实时性,同时降低整体系统负载。
方法三:遵守协议细节并实现优雅的错误处理
做法:仔细阅读官方文档: 特别关注rate limiting和flood control部分。对于Bot API,考虑使用webhook替代getUpdates轮询以接收实时更新。
实现指数退避重试: 当捕获到429 Too Many Requests或FLOOD_WAIT_X错误时,程序应自动暂停。等待时间应随重试次数指数级增加(例如,等待 2^n 秒,n为重试次数),并在等待后重试。
添加熔断机制: 如果某个账号连续多次触发严重错误,则将其暂时标记为“不可用”,放入冷却池,并启用备用账号接管其任务。
优点: 使软件行为更符合官方预期,增强鲁棒性。优雅的错误处理能自动应对临时性限制,保证采集任务长期稳定运行,避免账号被封禁。
 请求处理中...
请求处理中...










 企业QQ
企业QQ
 智能客服
智能客服





