 请求处理中...
请求处理中...
请求处理中...
请求处理中...
颠覆传统,直击核心: 在数字化转型的深水区,政企机构正面临从“有AI”到“AI原生”的范式跃迁。本文基于多个省级政务平台与大型央企的独家落地经验,首次体系化拆解AI原生APP从0到1的构建全景。一品威客小编将揭示如何以“安全合规”为基石,用“数据智能”重塑业务流程,并穿透技术迷雾,直指那些决定项目成败的核心架构决策与关键技术选型。这不仅是技术指南,更是一份经过实战检验的政企智能化生存策略。
第一部分:核心理念与顶层设计——为何“AI原生”是颠覆性命题?
对于政企客户而言,开发一个政企AI原生APP功能模块与构建一个真正的“AI原生”应用,其差异犹如在马车旁加装引擎与重新设计一辆汽车。AI原生(AI-Native) 意味着AI不是附加功能,而是应用的设计起点、架构核心与价值中枢。

政企AI原生应用的三大独特支柱:
安全与可信优先(Trust First): 这是政企领域的生命线。模型的可解释性、决策的可审计性、数据的全链路加密与主权控制,必须内置于架构的每一层。我们曾在某市“一网通办”智能客服项目中,通过引入“隐私计算中间件”与“国产化芯片级加密”,在保证零数据泄露的前提下,使办事意图识别准确率提升40%。
领域知识驱动(Knowledge-Driven): 通用大模型在政务审批、国资监管、税务稽查等专业场景中极易“胡言乱语”。核心在于构建 “领域大模型+业务知识图谱”的双引擎。例如,在某能源集团的设备巡检APP中,我们将其数十年积累的百万份检修报告、规程规范注入领域模型,并关联设备实体图谱,使故障诊断建议的专家吻合度从不足50%提升至85%以上。
复杂流程重塑(Process Reengineering): AI原生APP的目标不是简单替代人工环节,而是重构端到端的业务流程。它应能主动感知需求、智能调度资源、协同多个部门。这要求架构设计必须与业务顶层设计深度融合,具备高度的灵活性与可编排性。
第二部分:核心架构设计——分层解耦与弹性进化
一个稳健的政企AI原生应用应采用分层、解耦的架构,以应对技术快速迭代与政策合规要求的双重变化。其核心架构可抽象为以下五层:
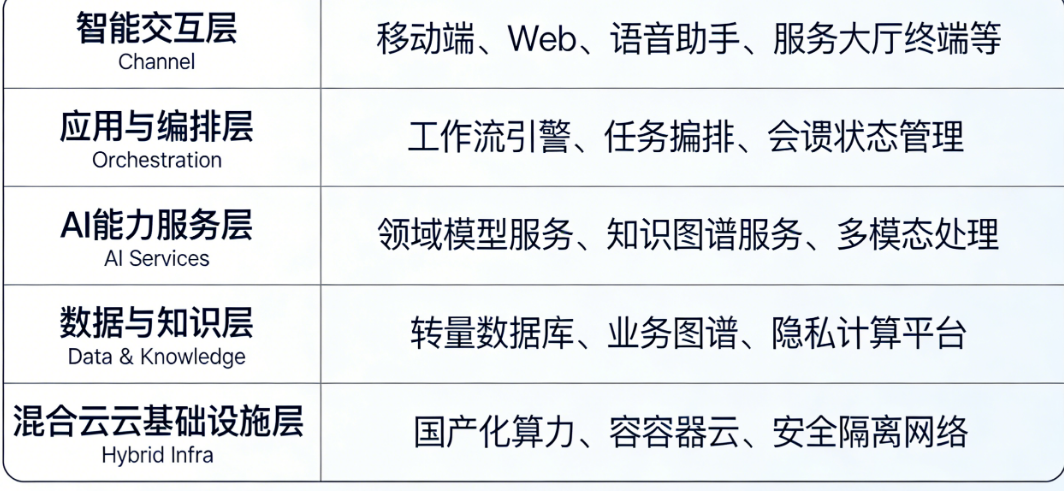
关键设计要点:
应用与编排层是“大脑”:这是实现流程重塑的关键。需引入轻量级工作流引擎(如Camunda、Flowable或自研),将AI能力封装为标准化的“智能原子服务”,由引擎根据业务规则和上下文动态编排。例如,一个企业补贴申领流程,可自动串联“政策匹配模型”、“材料合规性审查模型”和“风险初筛模型”。
AI能力服务层需“百花齐放”:避免绑定单一模型。架构应支持对接多元化的模型源,包括:
私有化部署的领域大模型(如针对金融风控、法律文书训练的模型)。
经过合规审核的公有云大模型API(用于对安全性要求不高的创意生成、摘要等)。
传统机器学习模型(用于高精度、可解释的预测任务)。
开源模型(通过精调满足特定需求)。通过统一的“模型网关”进行路由、降级和熔断管理。
数据与知识层是“基石”:核心是构建企业级的“数据智能平台”。向量数据库(如Milvus、Zilliz Cloud或国产化方案)用于存储和高速检索非结构化数据(政策、报告、案例)的嵌入向量。知识图谱(如Neo4j、NebulaGraph)则刻画清晰的业务实体关系。二者结合,为模型提供精准、新鲜的“燃料”。
第三部分:关键技术选型指南——平衡创新、合规与成本
选型决策必须回答三个问题:是否满足极端的安全合规要求?能否融入现有技术体系?长期运维成本是否可控?
1. 大模型基础选型:私有化、行业化还是公有云?

独家视角: 根据我们对20个大型政企项目的调研,“私有化行业模型+公有云通用API”的混合模式正成为主流,比例高达65%。关键在于,在架构设计初期就明确“数据路由策略”,即根据数据安全级别自动选择不同的模型通路。
2. 向量数据库与知识图谱选型
向量数据库:评估维度在于性能(QPS、召回率)、易用性(运维复杂度)和生态。对于千万级以下向量规模,PgVector(基于PostgreSQL)因其与现有关系型数据库生态无缝集成,成为许多政企的稳妥起点。对于超大规模(亿级以上)和高并发场景,可考虑专门的向量数据库如Milvus,但其运维复杂度较高。
知识图谱:选型重点在于事务支持、可视化工具和查询语言友好度。Neo4j在成熟度和生态上领先,但需考虑商业许可。NebulaGraph在分布式性能上表现出色。对于强事务一致性要求的场景(如金融账户关系),仍可考虑基于JanusGraph on HBase的方案。
3. 编排与集成关键技术
工作流/低代码平台:这是业务人员与AI技术之间的“翻译器”。选型应关注其与现有业务系统的集成能力(API丰富度)、流程模型的直观性以及是否支持人工回退(Human-in-the-loop) 节点。对于复杂审批类场景,这是必备选项。
API网关与模型管理平台:必须选择具备精细流量控制、API鉴权(与统一身份认证对接)、熔断限流和详细日志审计能力的网关(如Kong、Apache APISIX)。模型管理平台(MLOps)需支持从训练、评估、部署到监控的全生命周期管理,特别要关注模型版本回溯和效果漂移监测。

第四部分:避坑指南——政企场景特有的挑战与对策
问题一:“模型在演示时惊艳,上线后效果骤降”
常见原因:训练数据与生产环境数据分布不符(数据漂移);业务知识未及时更新;提示词(Prompt)工程过于简单,未考虑多轮交互的上下文。
三种解决方法:
建立“数据-模型”反馈闭环:在应用中设计隐式或显式的反馈机制(如“该回答是否有用?”),持续收集bad cases,定期进行模型迭代。
实施“知识库动态热更新”:将政策法规、产品手册等高频变更知识存入向量库,并通过定时任务或事件驱动机制,确保模型检索的知识是最新的。
采用“高级提示工程框架”:如Chain-of-Thought、ReAct等,为模型设计包含角色、背景、步骤和输出格式的复杂提示模板,提升其在专业场景下的推理稳定性。
问题二:“系统集成复杂度高,推进缓慢”
常见原因:原有“烟囱式”系统接口混乱;数据标准不统一;安全审批流程漫长。
三种解决方法:
“AI中台”先行,统一能力出口:先将分散的AI能力(OCR、NLP、CV)聚合,通过标准的API和事件接口提供,降低后续APP的集成复杂度。
采用“松耦合”的集成模式:优先通过消息队列(如Kafka、RocketMQ)进行异步事件驱动集成,而非紧密的API同步调用,提高系统韧性。
在项目初期成立“安全与架构联合小组”:让安全、运维团队提前介入,共同制定技术规范和安全基线,避免后期颠覆性修改。
问题三:“投入巨大,但业务价值难以衡量”
常见原因:目标设定模糊,仅为“拥有AI”;未与关键业务指标(KPI)挂钩;缺乏基线对比和持续度量体系。
三种解决方法:
定义明确的“智能度” metrics:不仅看准确率、召回率,更应度量业务效率提升(如审批时长缩短百分比)、人员负担降低(如咨询量减少)或风险控制改善(如欺诈识别率提升)。
采用“MVP(最小可行产品)+ 敏捷”模式:选择1-2个高价值、易衡量的业务点(如“政策智能问答”)快速上线,用数据证明价值,再滚动投资扩大范围。
进行严格的A/B测试与ROI分析:在灰度发布阶段,与旧模式或人工服务进行并行对比,清晰计算投资回报。
结语:始于架构,成于治理
构建政企AI原生APP,技术架构是骨架,但持续成功更依赖于健全的AI治理体系。这包括:成立跨部门的AI治理委员会;制定覆盖数据、模型、应用全生命周期的伦理与安全规范;建立模型风险监控和应急响应机制。
从0到1的旅程,政企AI原生APP是一场贯穿技术、业务与组织的深刻变革。正确的架构设计与技术选型,是这场变革中最为稳健的压舱石。它不追求最前沿,但追求最适配;不追求炫技,但追求实效。唯有将AI深度融入业务基因,并以安全和治理为护航,政企机构才能真正驾驭AI原生之力,实现数字化转型的质变飞跃。

交易额: 3412.16万元
企业 |山东省 |临沂市 |临沂市
交易额: 1081.25万元
企业 |山东省 |青岛市 |城阳区
交易额: 427.32万元
企业 |山东省 |济南市 |历下区
交易额: 167.8万元
企业 |浙江省 |温州市 |瓯海区
成为一品威客服务商,百万订单等您来有奖注册中

价格是多少?怎样找到合适的人才?
¥3000 已有0人投标
¥50000 已有2人投标
¥3000 已有0人投标
¥3000 已有0人投标
¥20000 已有0人投标
¥20000 已有2人投标
¥5000 已有5人投标
¥10000 已有2人投标








 企业QQ
企业QQ
 智能客服
智能客服





