 请求处理中...
请求处理中...
请求处理中...
请求处理中...
很多AI项目失败不是算法不行,而是数据划分从一开始就错了!这篇文章将直接告诉你一个残酷事实:超过60%的模型泛化失败问题,根源在于没有解决好【如何构建有效的训练/验证/测试集】这一根本问题。不是你的模型不够聪明,而是你给它的“考试题”本身就出错了!
想象一下:如果你让一个学生只刷10套模拟题就去高考,而他考前恰好把这10套题的答案全背下来了——这个学生在模拟考里每次都得满分,对吧?但真上了高考考场,看到完全没见过的题目,立马就懵了。这就是大部分AI模型面临的困境:在验证集上表现完美,一到真实场景就“见光死”。究其本质,就是因为在【如何构建有效的训练/验证/测试集】这个基础环节上存在严重缺陷,导致整个评估体系失真,模型的实际泛化能力成为了“玄学”。
今天,我就用最直白的方式,给你拆解数据划分的3大核心原则和4步标准化流程。读完这篇,你会彻底明白如何构建有效的训练/验证/测试集,掌握为什么那些看似“玄学”的划分技巧其实有章可循,也会获得一套能立即上手的实战方法,让你不再在这个基础但致命的问题上栽跟头。
一、数据划分为什么这么重要?(“奶茶钱”就能理解的比喻)
先问个问题:你训练模型是为了什么?肯定不是为了在训练数据上拿满分,而是为了它能在没见过的新数据上也能表现优秀,对吧?这就是“泛化能力”的核心。但要真正评估和提升这种能力,关键的第一步就是解决【如何构建有效的训练/验证/测试集】这个问题。 一个失败的划分,会直接导致你对模型泛化能力的判断完全失真——你以为它在“举一反三”,其实它只是在“死记硬背”你无意中泄露的答案。因此,深入理解并掌握【如何构建有效的训练/验证/测试集】,是确保你的模型能走向真实世界而非困在象牙塔里的第一道,也是最重要的一道防线。
如果把模型训练比作学生备考:
训练集 = 平时做的练习题(用来学习知识)
验证集 = 期中/月考(用来调整学习方法、发现弱点)
测试集 = 最终的高考(模拟真实场景,考完才知道真水平)
最致命的错误是什么? 就是让期中考试的题目混进了平时的练习题里!这样学生看似期中考试成绩很好,其实只是记住了答案,根本不知道自己真实水平。
在AI项目中,这个错误就叫 “数据泄露” ——验证集或测试集的信息,在训练过程中被模型“偷看”到了。结果就是验证分数虚高,上线后全面崩盘。

二、3大核心原则:别让数据划分成为“玄学”
原则1:数据同源但分布独立
“同源” 指的是所有数据都来自同一个业务场景或数据生成过程。
“分布独立” 指的是训练、验证、测试集之间的数据不能有“亲戚关系”。
举个例子:
假设你要做人脸识别模型,数据是从公司打卡系统收集的:
错误做法:把员工A周一、周三的照片放训练集,周二的放测试集——模型很容易认出这是同一个人,因为姿势、光线都类似。
正确做法:按人划分!员工A所有照片要么全在训练集,要么全在验证/测试集。这样才能真实测试模型能不能识别从未见过的人。
关键避坑点:警惕时间序列数据!如果你的数据是按时间顺序采集的,千万不要随机划分!一定要按时间切分,用过去的数据训练,预测未来的数据。
原则2:验证集要当“真正的考官”
很多人把验证集当成了“第二份练习题”——错了!验证集存在的唯一目的,就是客观评估模型的泛化能力。
记住这三个“不要”:
不要用验证集反复调参——调个三五次还行,调个几十上百次,验证集就成了“泄题考官”。
不要在验证集上选择最好的模型,然后直接在测试集上报告这个模型的成绩——这属于“作弊后还拿作弊成绩当真实水平”。
更不要用测试集来调参——这就相当于高考前把高考题做了一遍。
原则3:测试集要“一锤定音”且足够大
测试集是你最后的防线,是用来模拟真实上线后情况的。所以:
测试集一旦确定,就不能再碰——连看一眼分布都不行!
测试集要足够大,才能有统计意义。一般来说,至少要有几百到几千个样本(取决于任务复杂度)。
测试集要尽可能接近真实数据分布——如果真实场景中会有模糊图片,测试集里也要有。

三、4步标准化流程:从“打乱仗”到“标准化作战”
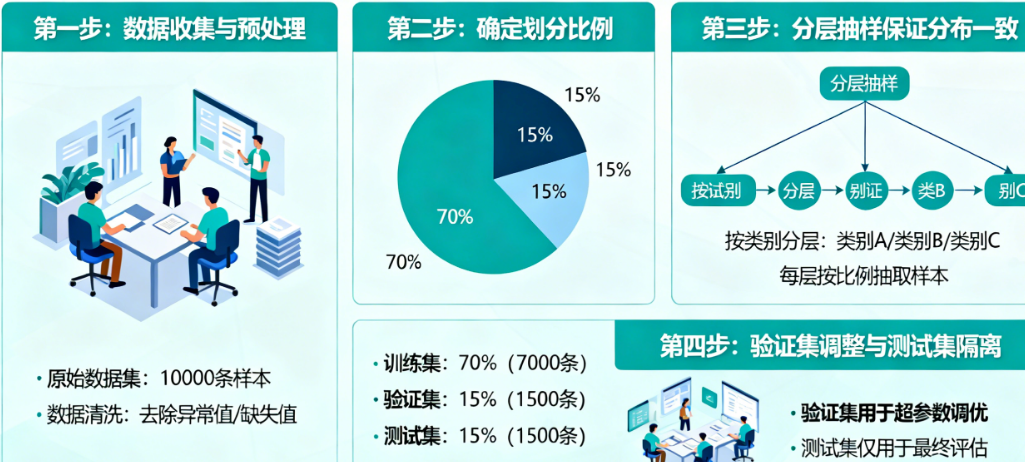
第1步:数据清洗与探索(别急着划分!)
先花至少30%的时间做这件事:
去掉重复样本——重复数据会让模型产生“这个人很重要”的错觉。
处理缺失值和异常值——决定是删除还是填补,但要在划分前统一处理规则。
可视化看一下分布——用简单的统计图表看看各类别比例、特征分布。这一步能帮你发现很多潜在问题。
新手常见坑:划分后再清洗,导致训练集和验证集的处理方式不同,引入人为偏差。
第2步:按业务逻辑确定划分策略(最关键的一步!)
这是最体现经验的一步。我总结了几种常见场景:
场景A:独立同分布数据(最常见)
比如图像分类、普通文本分类
方法:随机分层抽样
比例:7:2:1 或 6:2:2(训练:验证:测试)
关键:用 sklearn 的 train_test_split 时,一定要设置 stratify=y,保证各类别比例一致!
场景B:时间序列数据
比如销量预测、股票预测
方法:按时间顺序切分
示例:用1-10月数据训练,11月验证,12月测试
关键:测试集必须在时间上最靠后,模拟真实预测未来
场景C:分组数据(Grouped Data)
比如医疗影像(一个病人有多张片子)、用户行为数据(一个用户有多条记录)
方法:按组划分
核心原则:同一组的数据,绝对不能同时出现在训练集和验证/测试集!
第3步:执行划分并生成元数据
划分不只是分文件,要记录元数据:
python
# 示例:记录划分信息
划分时间:2024年1月15日
划分策略:按患者ID分层划分
训练集:患者ID为[1-700],共5000张图像
验证集:患者ID为[701-850],共800张图像
测试集:患者ID为[851-1000],共700张图像
特殊处理:已移除重复影像,缺失标注已补齐
这个记录文件要保存好!以后复现实验、分析错误都需要它。
第4步:划分后检查清单(很多人跳过这步,结果吃大亏)
花10分钟做下面5个检查:
数据泄露检查:有没有同一样本出现在两个集合中?(用MD5哈希值查重)
分布一致性检查:训练集和验证集的特征分布是否大致相同?(用直方图/KL散度)
类别平衡检查:每个集合中的类别比例是否相似?
业务合理性检查:这样划分是否符合真实业务场景?
大小合理性检查:测试集是否足够大,能有统计意义?
四、微调场景下的特殊处理(实战经验)
现在大模型微调很火,但数据划分错误是微调失败的第一大原因。
微调数据划分的黄金法则:
少数据也要划分——哪怕只有1000条数据,也要留出至少100条做测试。
领域分布匹配——如果你的微调数据和预训练数据差异很大,一定要确保验证/测试集能代表你的目标领域。
警惕指令数据泄露——在做指令微调时,相似的指令不能同时出现在训练和测试集。
举个真实案例:
我们团队曾微调一个客服问答模型,客户只有5000条历史对话数据。我们按7:2:1划分,但上线后发现效果很差。后来发现问题是:训练集里有很多“退款申请”类问题,但测试集里几乎没有——因为我们是随机划分的,没考虑业务季节性(年底退款多)。解决方案:改为按时间划分,用前10个月训练,第11个月验证,第12个月测试,效果立竿见影。
五、常见问答
Q1:我的数据太少了,可以不划分测试集吗?
可以,但要用交叉验证。不过交叉验证的结果更多是“模型选择”,不是“最终性能评估”。如果数据真的少到无法划分,至少要留出20%做验证。
Q2:划分比例到底怎么定?有标准答案吗?
没有绝对标准,但有经验法则:
数据量>10万:98:1:1都行(因为1%就是1000条,够测试了)
数据量1万-10万:7:2:1或6:2:2
数据量<1万:谨慎使用,考虑交叉验证
Q3:划分后发现训练集和验证集分布不一致,怎么办?
这是红色警报!说明划分策略有问题。先检查是不是随机种子问题,如果不是,可能要重新考虑划分策略(比如是不是应该按时间或分组划分)。
Q4:深度学习需要划分验证集吗?还是直接用测试集?
绝对需要验证集! 深度学习训练周期长,如果没有验证集来早停(Early Stopping),很容易过拟合。测试集是最后一道防线,训练过程中不能碰。
六、数据划分失败案例分析
数据划分失败?别懵!4个典型症状和你的自救指南
很多朋友训练模型时都会遇到一些“灵异事件”:明明验证集分数高得离谱,一上线就崩了;或者某个类别死活学不好。别急着怀疑人生,很可能问题出在最基础的一步——数据划分。
下面我整理了4个最常见的数据划分失败症状,你可以像查字典一样,对照自己的项目找原因、找解法。
症状一:验证集效果远好于测试集
你的感觉:模型在验证集上表现超神,精准率、召回率都95%+,你觉得稳了。但一到测试集,分数直接掉到70%甚至更低,心态瞬间崩了。
最可能的原因:验证集数据泄露到训练过程了。
通俗点说,就是模型在“训练时偷看了考题”。这就像你高考前,有人不小心把部分高考题混进了你的模拟卷,你做模拟考当然分数高,但真实水平其实没那么好。
具体是哪里泄露了?
时间序列没按时间划分:比如你做销量预测,用2023年全年数据随机划分。结果训练集里混入了12月的“未来数据”,验证集也包含12月数据,模型当然能“预测”得很好。但用完全独立的2024年1月数据测试时,就原形毕露。
分组数据随机划分了:比如医疗影像中,同一个病人的多张CT片,被随机分到了训练集和验证集。模型其实是通过“记住这个病人的特征”来在验证集得高分的,而不是真正学会了看病变。
有重复数据:数据清洗不彻底,同一个样本(或高度相似的样本)同时出现在训练集和验证集。
自查方法(三步走):
第一步:检查划分代码,是不是该用GroupKFold或按时间切分的地方,误用了随机划分?
第二步:计算一下训练集和验证集样本之间的相似度(比如用MD5哈希查文本,或用特征向量余弦相似度查图像),看看有没有“双胞胎”样本。
第三步:如果是时间数据,画个时间分布图,一眼就能看出有没有时间穿越。
急救方案:
立即停止当前训练!重新按正确的逻辑(按时间、按患者ID、按用户ID分组)划分数据。记住一个铁律:能泄露身份信息的单位,必须整体划分。
症状二:训练集和验证集效果都很高,但上线后很差
你的感觉:训练过程非常顺利,损失曲线完美下降,验证曲线紧紧跟随,一切迹象都表明这是个好模型。但部署到生产环境,用户反馈“这模型不太灵啊”,业务指标也毫无提升。
最可能的原因:你的测试集(乃至整个实验数据)都不代表真实世界。
你的数据太“干净”、太“理想”了。比如:
你训练的猫狗分类器,用的都是高清专业动物摄影图片。但用户上传的是模糊的、光线很暗的、猫狗只占画面一小部分的手机快照。
你做情感分析的文本,来自清洗过的正规商品评论。但真实用户评论里有各种网络用语、错别字、表情符号,还有“呵呵”这种阴阳怪气的词。
自查方法:
对比一下你的测试集数据和线上实时收集的最初100条真实数据。用肉眼看看,或者算几个关键特征的分布(如图像亮度分布、文本长度分布、词汇表差异)。差异很可能大得吓你一跳。
急救方案:
立即收集真实的线上数据,哪怕只有几百条,用它构建一个“真实分布测试集”。
重新评估模型在这个新测试集上的表现,这才是它真实的水平。
数据增强:用更加“狂野”的数据增强策略(模拟模糊、遮挡、噪声、网络用语替换等),让模型在训练时见见“世面”。
症状三:验证集效果波动很大
你的感觉:每次训练,甚至同一次训练的不同阶段,验证集上的指标(比如准确率)像坐过山车一样,忽高忽低,完全没有规律。你根本不知道该相信哪一个结果,也没法做早停(Early Stopping)决策。
最可能的原因:验证集太小了,或者验证集分布太偏了。
验证集本质上是一次抽样。如果抽样数量太少,或者抽到的样本刚好比较“怪”(比如全是难样本或全是简单样本),那评估结果就像抛硬币,随机性很大,不能反映模型真实水平。
自查方法:
算一下你的验证集大小。对于分类任务,一个经验法则是:验证集每个类别的样本数最好不少于50个。如果你的某个稀有类别在验证集里只有5个样本,那么模型在这个类别上90%的准确率,可能只是因为猜对了4个而已,毫无统计意义。
急救方案:
增大验证集:从训练集里再匀一些数据给验证集,哪怕牺牲一点训练数据量。稳定性比多练几轮更重要。
使用K折交叉验证:如果数据总量实在有限,就用K折交叉验证来代替单次划分。这样你能得到K个评估结果,取其平均值和方差,对模型性能的估计会更稳健。
分层抽样保证分布:确保划分时用了分层抽样,让验证集里各个类别的比例和训练集、真实世界基本一致。
症状四:某个类别在测试集上表现特别差
你的感觉:看整体准确率还行,但一打开分类报告,发现“类别A”的精确率或召回率低得可怜,甚至是0。模型好像对这个类别“瞎了”一样。
最可能的原因:类别分布不一致,特别是“长尾”或“稀有”类别。
这是非常经典的问题。比如一个10分类问题,其中9个类别各有1万张图,但第10个类别只有100张图。如果你随机划分,这个稀有类别在训练集里可能只有70张,在验证集和测试集里各只有15张。模型在训练时根本没见过足够的样本来学习它的特征,当然学不好。
自查方法:
分别统计训练集、验证集、测试集中每个类别的样本数量,做成一个表格或柱状图。你一眼就能看出哪个类别在哪个集合里“势单力薄”。
急救方案:
使用分层划分:这是首选!在调用划分函数时(如 train_test_split),使用 stratify=y 参数。计算机会自动保证每个集合的类别比例和原始数据集相同。
对稀有类别过采样:在训练集中,对样本数少的类别进行复制或数据增强,增加其权重,让模型多关注它们。
调整损失函数:使用带类别权重的损失函数(如 Focal Loss 或加权交叉熵),在计算损失时给稀有类别更高的权重,惩罚模型对它们的误判。
最后总结一下
数据划分就像盖房子的地基,地基歪了,房子盖得再漂亮也危险。下次你的模型出现奇怪表现时,别第一时间去调复杂的网络结构或玄学的超参数。先冷静下来,回到起点,用上面的指南诊断一下你的数据划分。
花一小时检查并修正划分问题,比你花一星期盲目调参要有效100倍。磨刀不误砍柴工,这个道理在AI时代,依然成立。
行动起来:你的下一步
如果你看完觉得:“道理都懂,但实操还是复杂”,或者“团队里没人擅长这个”,那我给你指条明路。
一品威客这个平台,能帮你快速找到靠谱的数据科学专家。具体怎么用呢?
任务大厅发布需求:如果你有明确的数据划分需求,比如“帮我审核现有数据划分方案”或“为我的医疗影像数据设计划分策略”,可以在这里详细描述你的业务场景、数据量、现有问题,会有专业团队给你报价和方案。
人才大厅直接找人:如果你需要长期合作的数据伙伴,可以在这里筛选有“数据策略”、“机器学习工程”标签的人才,看看他们的过往项目经验和客户评价。
商铺案例参考:不确定对方水平?去服务商的商铺页面,看他们做过的真实案例。特别是找那些做过和你类似行业(比如金融风控、医疗AI、推荐系统)案例的团队。
雇主攻略学习:如果你是第一次找外包,一定要先看这里的指南。教你如何写清晰的需求文档、如何设定验收标准、如何管理项目进度——这些能帮你避掉很多坑。
最关键的是:在沟通时,直接把你这篇文章里学到的“3大原则”、“4步流程”作为验收标准的一部分。让对方知道你是懂行的,这样对方会更认真,也更容易找到真正专业的人。
数据划分不是一次性工作,而是AI项目的基础设施。把它做扎实了,后面的模型训练、调优、部署,才会事半功倍。现在就去检查一下你的项目,数据划分真的做对了吗?


价格是多少?怎样找到合适的人才?
¥3000 已有0人投标
¥50000 已有2人投标
¥3000 已有0人投标
¥3000 已有0人投标
¥20000 已有0人投标
¥20000 已有2人投标
¥5000 已有5人投标
¥10000 已有2人投标








 企业QQ
企业QQ
 智能客服
智能客服





