 请求处理中...
请求处理中...
请求处理中...
请求处理中...
你在玩VR游戏时有没有遇到过这种情况?按下开火键,半秒钟后才听到枪声;或者在虚拟会议中发言,对方听到的声音总是慢半拍?这种延迟问题,简直就是沉浸式体验的“杀手”。更糟糕的是,在AI音频生成应用中,延迟问题被放大了——因为生成音频本身就需要时间!
今天咱们不聊那些让人头大的数学公式,就像朋友聊天一样,我来告诉你AI音频生成的延迟到底卡在哪里,以及怎么用模型轻量化和边缘计算这些“黑科技”来解决它。这就是AI音频生成延迟优化指南要解决的核心问题。准备好了吗?咱们这就开始优化之旅,一起探索这本实用的AI音频生成延迟优化指南!

一、延迟的“三座大山”:为什么AI音频生成总是慢半拍?
先搞明白延迟是从哪来的,才能对症下药。AI音频生成的延迟,主要来自三个环节:
第一座山:模型推理时间——AI“思考”要多久?
这是AI音频生成延迟优化指南要解决的最核心问题。你的音频生成模型(比如VITS、WaveNet)需要多少时间来“思考”并生成音频?一个复杂的模型可能需要几百毫秒甚至几秒钟,这对于实时应用来说简直是灾难。理解并攻克这一瓶颈,是AI音频生成延迟优化指南中的首要任务。
举个例子:你想让AI实时生成游戏角色的对话声音。如果模型推理需要500毫秒,那角色就会在你输入后半秒才开口——这在快节奏的游戏中完全无法接受。
第二座山:数据传输延迟——声音“在路上”的时间
就算模型推理很快,生成的声音数据还需要传输到播放设备。如果用的是云端生成方案,数据要在你的设备、云端服务器、再回到你的设备之间跑个来回。这个“网络往返时间”可能又是几十到几百毫秒。
更糟的是网络不稳定的时候——声音数据包丢失、需要重传,延迟就更加不可预测了。
第三座山:音频处理流水线——每个环节都在“拖后腿”
AI音频生成不是一步到位的,而是一个流水线:输入处理 → 模型推理 → 后处理 → 编码传输 → 解码播放。每个环节都有一点延迟,加起来就很可观了。
特别是音频编码/解码这个环节。为了减少传输数据量,通常会对音频进行压缩编码(比如用Opus编码),接收端再解码播放。这个过程虽然节省了带宽,但也增加了延迟。
二、模型轻量化:给AI模型“瘦身减肥”
好了,知道问题在哪了,咱们开始解决。第一个大招:模型轻量化。说白了,就是让AI模型变得又小又快,但效果还不能差太多。
方法1:知识蒸馏——让“小学生”模仿“大学生”
这招特别巧妙。我们有一个效果很好但很笨重的大模型(“大学生”),用它来教一个小巧的模型(“小学生”)。不是教它标准答案,而是教它“思考方式”。
具体怎么做呢?让大模型生成很多音频样本,同时记录它中间层的“特征表示”。然后用这些样本来训练小模型,不仅要让小模型生成的音频像大模型,还要让小模型中间层的特征表示也像大模型。
效果:小模型能达到大模型80%-90%的效果,但大小可能只有1/10,推理速度提升5-10倍。这对延迟优化来说是巨大的提升!
方法2:模型剪枝——去掉“没用”的部分
神经网络里有很多参数,但有些参数其实“贡献不大”。就像你背包里带了很多东西,但有些根本用不上。模型剪枝就是把这些“没用”的参数去掉。
有几种剪枝策略:
结构化剪枝:直接去掉整个神经元或卷积核。这就像把背包里某个完全用不上的物品整个拿出来。
非结构化剪枝:去掉单个权重参数。这就像把物品里用不上的零件拆掉,但保留物品本身。
迭代剪枝:不是一次剪完,而是训练 → 剪枝 → 再训练 → 再剪枝,逐步精简。
关键技巧:剪枝后一定要再训练(fine-tune),让模型适应新的结构。不然性能会下降得很厉害。
方法3:量化压缩——从“高精度”到“够用就行”
神经网络通常用32位浮点数(float32)存储参数,精度很高,但也很占空间。量化就是降低精度,比如用8位整数(int8)甚至4位来表示参数。
举个例子:float32的3.1415926,量化成int8可能就变成3了。看起来精度损失了,但对音频生成来说,很多时候“够用就行”。
量化有两种方式:
训练后量化:先训练好模型,再量化参数。简单快捷,但可能有精度损失。
量化感知训练:在训练过程中就模拟量化的效果,让模型学会在低精度下也能工作。效果更好,但训练更复杂。
实测效果:从float32量化到int8,模型大小减少75%,推理速度提升2-4倍,对大多数音频生成任务来说,音质损失几乎听不出来。

三、边缘计算:让AI在“家门口”工作
模型轻量化解决了“思考慢”的问题,但还有网络延迟这个大山。这时候就需要边缘计算登场了。
边缘计算的核心理念:计算离数据更近
传统云计算是把所有数据都传到云端,处理完再传回来。边缘计算是把计算资源部署在离用户更近的地方——可能是你的手机、家里的路由器、本地的边缘服务器。
对AI音频生成来说,这意味着:
数据不用跑远路,减少了网络往返时间
避免了网络拥塞的影响
带宽要求更低(因为不用传大量原始数据)
部署策略:分层处理,各司其职
不是所有计算都要在边缘完成。聪明的做法是分层处理:
第一层:设备端(超低延迟,简单任务)
在手机、VR头显上部署极轻量级模型,处理最紧急的、对延迟最敏感的任务。比如:
基础的语音合成(TTS)
简单的音效生成
实时音频滤波处理
第二层:边缘服务器(中等延迟,复杂任务)
在本地机房或5G基站部署中型模型,处理需要更多算力但不要求极低延迟的任务。比如:
高质量的音乐生成
复杂的语音转换(Voice Conversion)
多说话人语音合成
第三层:云端(可接受延迟,最复杂任务)
在云端数据中心部署完整的大模型,处理那些对延迟不敏感、但要求最高质量的任务。比如:
模型训练和优化
批量音频生成
超高质量的音乐创作
关键技术:模型分割与协同推理
有时候一个模型太大,一台边缘设备跑不动,怎么办?把模型拆开,不同部分在不同地方跑。
比如一个语音合成模型,可以拆成:
文本处理部分(较小)→ 在设备端运行
声学模型核心(中等)→ 在边缘服务器运行
声码器部分(中等)→ 在边缘服务器运行
设备端处理完文本,把中间结果发给边缘服务器,服务器生成音频后再发回来。这样既利用了边缘服务器的算力,又减少了数据传输量(中间结果通常比原始数据小)。
四、进阶技巧:把这些组合起来用
单独用模型轻量化或边缘计算都有用,但组合使用效果更炸裂。
技巧1:动态模型切换
根据网络条件和设备状态,动态选择使用哪个模型。
网络好、电量足的时候 → 用质量更好的模型
网络差、电量低的时候 → 用更轻量的模型
完全离线的时候 → 用设备端的极简模型
这需要前端有智能的模型选择器,能实时评估条件并做出最优选择。
技巧2:预测性生成
AI不只是被动响应,还能主动预测你要什么声音,提前生成。
在游戏中:预测玩家下一步可能的行为,提前生成对应的音效
在会议中:根据对话内容,预测下一个人可能要说什么,提前准备语音合成
这需要结合用户行为分析和上下文理解,技术难度高,但延迟优化效果最好——因为声音已经提前准备好了,等你需要时直接播放。
技巧3:流式生成与播放
不要等整个音频都生成完了再播放,而是生成一点,播放一点。
就像视频流媒体一样,音频也可以流式生成。模型生成第一段音频的同时,就开始播放,然后继续生成后面的部分。这对长文本的语音合成特别有用。
技术关键是保证生成速度 > 播放速度,否则就会“卡壳”。这需要精确的缓冲区管理和速度匹配算法。
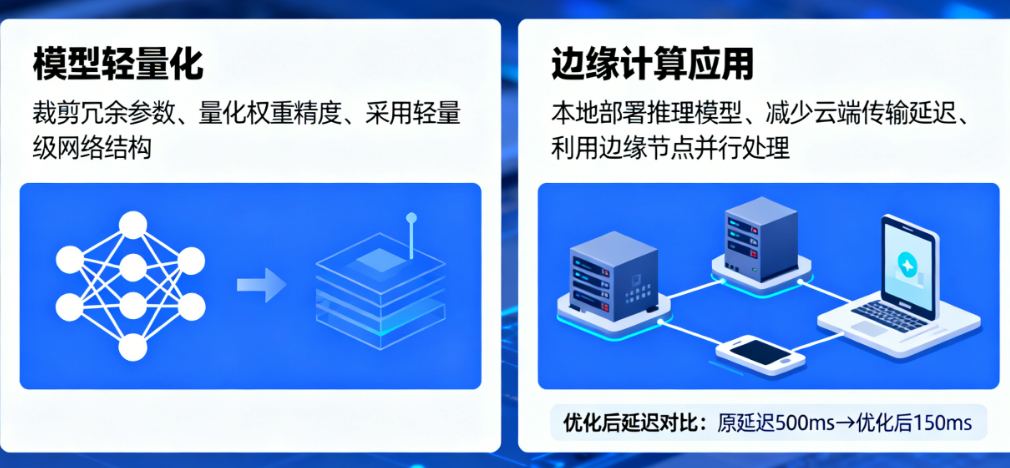
五、常见问题(FAQ)
Q:模型轻量化一定会损失音质吗?损失有多大?
A:一定会有损失,但可以控制在可接受范围内。通过知识蒸馏+量化+剪枝的组合,通常能把模型压缩到原来的1/4-1/10大小,推理速度提升3-10倍,而音质损失普通人几乎听不出来(在AB对比测试中,MOS分可能只下降0.1-0.3)。关键是找到那个“甜点”——在可接受的音质损失下,获得最大的速度提升。
Q:边缘计算需要多少投入?小公司玩得起吗?
A:现在越来越玩得起了!公有云厂商都推出了边缘计算服务(比如AWS Outposts、Azure Stack Edge、阿里云边缘节点服务),你可以按需租用,不用自己建机房。对于初创公司,可以从云厂商的边缘服务开始,用量大了再考虑自建。入门成本可能就每月几千元。
Q:实时AI音频生成的最低延迟能做到多少?
A:这要看具体场景和要求。目前的技术水平:
设备端轻量模型:20-50毫秒(端到端,从输入到播放)
边缘服务器+轻量模型:50-100毫秒
云端+标准模型:200-500毫秒
对于大多数实时交互应用(如游戏、VR),需要控制在100毫秒以内;对于实时通话,需要控制在50毫秒以内。通过优化,是完全可以做到的。
Q:有没有开源的优化工具可以直接用?
A:当然有!推荐几个:
TensorRT(NVIDIA):专门的推理优化工具,支持模型量化和加速
OpenVINO(Intel):英特尔家的优化工具,对CPU特别友好
ONNX Runtime:微软开源的推理引擎,支持多种硬件和量化方案
TFLite(Google):专为移动和边缘设备优化的TensorFlow版本
这些工具都有详细的文档和示例,跟着做就能上手。
六、行动起来:你的优化路线图
如果你正在做AI音频生成项目,被延迟问题困扰,我建议按这个路线图来:
第一周:基准测试
先别急着改代码,搞清楚现在的延迟到底是多少,瓶颈在哪。用工具测量每个环节的时间:模型推理、数据传输、音频处理。知道问题在哪,才能有的放矢。
第二到四周:模型轻量化
从最简单的开始:训练后量化。这通常只需要几行代码,但效果立竿见影。如果效果满意,再尝试知识蒸馏,训练一个更小的学生模型。
第五到八周:边缘计算部署
选一个边缘计算平台(建议从公有云厂商的开始),把量化后的模型部署上去。测试从设备到边缘服务器的延迟,优化网络连接。
第九周起:进阶优化
如果还有延迟问题,再考虑流式生成、预测性生成、动态模型切换这些高级技巧。这些需要更多的工程工作,但能把延迟压到极限。
记住:优化是个持续过程,不是一蹴而就的。随着硬件进步、算法改进,总有新的优化空间。
需要专业的AI音频延迟优化解决方案?您需要资深的音视频技术团队!
上一品威客,精准对接实时音频技术专家!
无论您是在开发VR/AR应用、实时语音交互产品,还是需要优化现有的AI音频生成系统,一品威客任务大厅都是发布需求的理想平台。清晰描述您的延迟优化目标和当前技术栈,即可快速获得多家专业服务商的针对性方案与合理报价。
希望直接招募核心人才?一品威客人才大厅拥有海量经过认证的“实时音频工程师”、“AI模型优化专家”、“边缘计算架构师”,您可以直接查看他们的技能证书、成功案例与项目经验,快速组建专属攻坚团队。
在一品威客商铺案例区,您可以深入了解游戏音频、实时通讯、智能语音设备等领域的低延迟优化成功案例,获取宝贵的工程实践经验与技术选型参考。
如果您是技术外包的新手,一品威客雇主攻略学习专栏是您的必备指南。从技术需求撰写、服务商技术评估到项目管理,这里有系统化的知识帮助您规避风险,确保项目在预算内按时交付,达到预期的性能指标。
立即行动,在一品威客开启您的AI音频延迟优化项目,让您的产品体验真正“实时”流畅!


价格是多少?怎样找到合适的人才?
¥5000 已有5人投标
¥1200 已有0人投标
¥10000 已有0人投标
¥1000 已有0人投标
¥10000 已有4人投标
¥1000 已有20人投标
¥20000 已有0人投标
¥50000 已有0人投标








 企业QQ
企业QQ
 智能客服
智能客服





