 请求处理中...
请求处理中...
请求处理中...
请求处理中...
引言:当AI遇见前后端分离
想象这样一个场景:你正在开发一款智能客服应用,需要在网页中嵌入一个AI对话助手。前端工程师画好了界面,后端工程师搭好了服务器,现在只差最后一步——把AI能力接进来。
最简单的做法是什么?前端直接调用OpenAI的API,几行代码就能搞定。但你很快会发现,这样做有几个致命问题:API密钥暴露在浏览器里,任何人都能扒走;请求没有经过任何封装,想换个模型得改所有代码;没有限流和监控,万一用户疯狂调用,月底账单会让你怀疑人生。
这正是前后端分离架构大显身手的场景。将AI接口的调用封装在后端,前端只负责展示和交互,不仅能解决安全问题,还能让系统更健壮、更灵活、更容易维护。
本文将带你深入了解如何在前后端分离架构中“优雅”地集成AI接口。所谓优雅,不是简单地封装一个API调用,而是从架构设计、安全防护、性能优化到可扩展性,全方位打造一个经得起考验的AI集成方案。
一、为什么不能在浏览器里直接调AI接口?
很多初学者第一次接触AI接口时,会直接在React或Vue代码里这样写:
javascript
// 这是错误示范,千万别这么干
const response = await fetch('https://api.openai.com/v1/chat/completions', {
method: 'POST',
headers: {
'Authorization': 'Bearer sk-xxxxxxxxxxxxx', // API密钥直接暴露!
'Content-Type': 'application/json'
},
body: JSON.stringify({...})
});
这段代码跑起来没问题,但它埋下了几个定时炸弹:
安全风险:所有前端代码都对用户可见,你的API密钥会出现在浏览器开发者工具的Network面板里。恶意用户扒走你的密钥,可以随意调用接口,产生的费用全算在你头上。
无法控制调用频率:没有限流机制,用户可能一秒发几百个请求,你的账号很快就会被限流或封禁。
缺乏监控和日志:出了问题,你不知道是谁、在什么时候、调了什么接口。
模型锁定:今天用OpenAI,明天想换成国产模型?你得修改所有前端代码,逐个页面排查。
把AI接口的调用放到后端,这些问题迎刃而解。API密钥藏在服务器上,前端根本看不到;可以在后端实现限流、缓存、监控;切换模型只需修改后端的一个文件,前端完全无感知。
二、分层架构:让AI能力成为可插拔的模块
一个优雅的AI集成方案,应该让AI能力像乐高积木一样,需要时插上,不需要时取下,不影响系统其他部分。推荐采用三层架构:
表现层:只管展示和交互
这一层就是你的前端代码,React、Vue、Next.js都行。它只负责两件事:收集用户输入并发送到后端,接收后端返回的数据并渲染到界面上。AI接口的具体细节,前端完全不关心。
以React为例,一个干净的AI聊天组件应该长这样:
javascript
function Chat() {
const [input, setInput] = useState('');
const [messages, setMessages] = useState([]);
const sendMessage = async () => {
// 前端只关心:用户说了什么,后端返回了什么
const response = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message: input })
});
const data = await response.json();
setMessages([...messages,
{ role: 'user', content: input },
{ role: 'assistant', content: data.reply }
]);
setInput('');
};
return (/* UI组件 */);
}
注意,前端完全不知道后端调的是OpenAI还是文心一言,是GPT-4还是Claude。这种解耦让后续的技术栈切换变得极其轻松。
业务逻辑层:处理AI之外的“杂事”
这一层通常用Node.js、Python、Java等后端语言实现。它负责:
请求验证:用户有没有登录?输入内容是否合法?
限流控制:这个用户今天已经调了多少次?
上下文管理:多轮对话的历史记录怎么存?
缓存处理:相同的问题能不能直接返回缓存结果?
示例代码(Node.js/Express):
javascript
app.post('/api/chat', async (req, res) => {
try {
const { message } = req.body;
const userId = req.user.id; // 从JWT中解析用户身份
// 1. 限流检查:每分钟最多30次
const callCount = await redis.incr(`rate:${userId}`);
if (callCount > 30) {
return res.status(429).json({ error: '调用太频繁,请稍后再试' });
}
// 2. 获取对话历史(最近10条)
const history = await getConversationHistory(userId);
// 3. 调用模型服务层
const reply = await modelService.chat(message, history);
// 4. 保存新对话
await saveConversation(userId, message, reply);
res.json({ reply });
} catch (error) {
// 统一错误处理
res.status(500).json({ error: '服务暂时不可用' });
}
});
这一层充当了“看门人”的角色,把脏活累活都包了,让模型服务层可以专注于AI推理。
模型服务层:封装所有AI细节
这是最核心的一层,它封装了所有与AI接口相关的细节。设计良好的模型服务层应该具备以下特征:
统一接口:不管底层是OpenAI还是国产模型,对外暴露的方法应该是一样的。
javascript
// modelService.js - 统一接口定义
class ModelService {
async chat(message, history) {
// 子类实现具体逻辑
}
}
// OpenAI实现
class OpenAIService extends ModelService {
async chat(message, history) {
const response = await fetch('https://api.openai.com/v1/chat/completions', {
headers: { 'Authorization': `Bearer ${process.env.OPENAI_KEY}` },
body: JSON.stringify({ messages: this.buildMessages(message, history) })
});
return response.choices[0].message.content;
}
}
// 文心一言实现
class ErnieService extends ModelService {
async chat(message, history) {
// 文心一言的接口参数可能完全不同
// 但对外返回的结果格式保持一致
}
}
动态路由:可以根据场景自动选择最佳模型。
javascript
class ModelRouter {
route(prompt) {
// 简单问题用便宜的小模型
if (prompt.length < 50 && this.isSimpleQuestion(prompt)) {
return new LightweightModel();
}
// 复杂问题用大模型
return new GPT4Model();
}
}
这种设计让模型切换变成配置项的事情,哪天OpenAI涨价了,改一行代码就能切到国产模型。
三、API设计:前后端契约怎么定?
前后端分离的核心是约定好API的格式。一个好的API设计应该让前端用得顺手,后端改得轻松。
请求格式
建议统一使用POST + JSON格式,即使只是简单查询也保持一致性:
json
POST /api/v1/chat
{
"message": "你好,今天天气怎么样?",
"session_id": "abc123", // 可选,用于多轮对话
"options": {
"temperature": 0.7, // 可选,控制随机性
"max_tokens": 500 // 可选,控制回复长度
}
}
响应格式
响应格式要稳定,且包含足够的元数据:
json
{
"success": true,
"data": {
"reply": "你好!今天的天气晴朗,气温15-25度。",
"session_id": "abc123",
"tokens_used": 45
},
"meta": {
"latency_ms": 380,
"model": "gpt-3.5-turbo"
}
}
出错时也要有统一格式:
json
{
"success": false,
"error": {
"code": "RATE_LIMITED",
"message": "调用次数超限,请1分钟后再试",
"retry_after": 60
}
}
对于长文本生成场景,可以支持流式响应(SSE),让前端实现打字机效果,用户体验会好很多。
四、安全防线:守住你的API密钥和用户数据
把AI调用移到后端后,安全防线需要从几个层面构建:
认证与授权
所有AI接口请求必须经过身份验证。推荐使用JWT机制:前端登录后拿到token,每次请求都带上;后端验证token有效后才处理请求。
javascript
// 中间件示例
function authenticate(req, res, next) {
const token = req.headers.authorization?.split(' ')[1];
if (!token) return res.status(401).json({ error: '未认证' });
try {
const decoded = jwt.verify(token, process.env.JWT_SECRET);
req.user = decoded;
next();
} catch (error) {
res.status(401).json({ error: 'token无效' });
}
}
限流控制
AI接口调用是要花钱的,必须做好限流。可以使用令牌桶算法,对每个用户或每个IP单独控制:
javascript
// Redis实现限流
const key = `ratelimit:${userId}`;
const current = await redis.incr(key);
if (current === 1) {
await redis.expire(key, 60); // 60秒过期
}
if (current > 30) { // 每分钟最多30次
return res.status(429).json({ error: '调用太频繁' });
}
输入过滤
用户输入的内容可能包含恶意代码或敏感词,后端必须做过滤:
javascript
function sanitizeInput(text) {
// 1. 去除XSS脚本
text = text.replace(/< scriptb[^<]*(?:(?!)<[^<]*)*/gi, '');
// 2. 敏感词过滤(可用第三方库)
text = sensitiveWordFilter(text);
// 3. 长度限制
return text.substring(0, 2000);
}
传输加密
所有API请求必须走HTTPS,配置HSTS头强制使用安全连接。敏感数据在传输前可以用AES-256加密。
五、性能优化:让AI响应不再“卡顿”
AI接口的一大痛点就是慢——大模型推理动辄几秒。在前后端分离架构中,可以从几个角度优化:
缓存策略
对于常见问题,可以直接缓存结果,避免重复调用:
javascript
// 使用Redis缓存
const cacheKey = `ai:${hash(userMessage)}`;
const cached = await redis.get(cacheKey);
if (cached) {
return JSON.parse(cached);
}
// 没有缓存,调用模型
const result = await callModel(userMessage);
await redis.setex(cacheKey, 3600, JSON.stringify(result)); // 缓存1小时
return result;
异步处理
对于不要求实时响应的场景,可以用消息队列异步处理:
javascript
// 用户请求先入队,返回任务ID
const taskId = uuid();
await queue.add({ taskId, message: userMessage });
res.json({ taskId, status: 'processing' });
// 用户通过轮询或WebSocket获取结果
连接池管理
高并发场景下,合理管理HTTP连接能显著提升性能:
javascript
// 配置连接池
const httpAgent = new http.Agent({
keepAlive: true,
maxSockets: 50, // 最大并发连接数
maxFreeSockets: 20, // 空闲保持的连接数
timeout: 60000 // 超时时间
});
const response = await fetch(url, {
agent: httpAgent,
// ...
});
模型分级
对于简单任务,调用轻量级模型快速响应;只有复杂任务才调用大模型。这种“分层智能”策略可以在保证体验的同时大幅降低成本。某物流企业的实践显示,采用混合推理架构后,平均响应时间从450ms降至180ms,成本降低35%。
六、监控与运维:别等出事了再补救
AI接口集成上线后,必须有完善的监控体系:
核心指标
调用量:每小时/每天调用次数
响应时间:P50、P95、P99延迟
错误率:4xx/5xx状态码占比
token消耗:方便成本核算
模型分布:各个模型的调用占比
告警规则
设置合理的告警阈值,比如:
错误率连续5分钟超过5%
P99延迟超过3秒
调用量突增超过正常值3倍
降级方案
当AI服务不可用时,要有备用方案:
javascript
async function callModelWithFallback(message) {
try {
// 先调用主模型(比如GPT-4)
return await callGPT4(message);
} catch (error) {
// 主模型挂了,降级到备用模型(比如Claude或本地小模型)
logger.warn('GPT-4调用失败,降级到备用模型', error);
return await callFallbackModel(message);
}
}
七、实战示例:一个完整的AI聊天后端
最后,用一个完整的Express示例串起所有概念:
javascript
import express f rom 'express';
import rateLimit f rom 'express-rate-limit';
import cors f rom 'cors';
import { ModelRouter } f rom './models/ModelRouter.js';
import { authenticate } f rom './middleware/auth.js';
import { cacheMiddleware } f rom './middleware/cache.js';
const app = express();
const modelRouter = new ModelRouter();
// 中间件
app.use(cors());
app.use(express.json());
app.use(authenticate);
// 限流器:每个用户每分钟30次
const limiter = rateLimit({
windowMs: 60 * 1000,
max: 30,
keyGenerator: (req) => req.user.id,
message: { error: '调用太频繁,请稍后再试' }
});
// AI聊天接口
app.post('/api/v1/chat', limiter, cacheMiddleware, async (req, res) => {
try {
const { message, session_id } = req.body;
const userId = req.user.id;
// 参数校验
if (!message || message.length > 2000) {
return res.status(400).json({ error: '消息内容不合法' });
}
// 获取对话历史
const history = await getHistory(userId, session_id);
// 选择合适模型
const model = modelRouter.selectModel(message);
// 调用模型
const startTime = Date.now();
const reply = await model.chat(message, history);
const latency = Date.now() - startTime;
// 记录调用日志
await logAICall({
userId,
model: model.name,
tokens: reply.tokens,
latency,
success: true
});
// 返回结果
res.json({
success: true,
data: {
reply: reply.text,
session_id: session_id || generateSessionId()
},
meta: { latency_ms: latency, model: model.name }
});
} catch (error) {
// 错误处理
console.error('AI调用失败:', error);
await logAICall({
userId: req.user.id,
success: false,
error: error.message
});
res.status(500).json({
success: false,
error: {
code: 'AI_SERVICE_ERROR',
message: 'AI服务暂时不可用,请稍后重试'
}
});
}
});
app.listen(3000, () => {
console.log('AI服务已启动,端口3000');
});
常见问答
问:前端真的完全不能知道调了哪个模型吗?
答:前端可以通过响应头或meta字段知道模型信息,但这不影响安全性。关键是API密钥不能暴露,模型名称本身不是敏感信息。
问:多个AI接口怎么管理API密钥?
答:建议使用环境变量或专门的密钥管理服务(如AWS KMS、HashiCorp Vault),密钥轮换时要确保新旧密钥并行一段时间,避免服务中断。
问:如何处理模型返回的流式数据?
答:前端用EventSource或WebSocket接收流式数据,后端用Server-Sent Events(SSE)推送。实现时要注意连接超时、断线重连等问题。
问:用户上传图片怎么办?
答:如果是多模态模型,建议前端先上传图片到对象存储(如OSS),把URL传给后端;后端再将URL传给AI接口。避免直接传输大文件导致请求超时。
问:怎么测试AI接口集成?
答:单元测试层面mock模型调用;集成测试层面用测试账号调用真实接口(但控制频率);压测层面模拟高并发,验证限流和降级机制是否生效。
结语:优雅是一种设计态度
在前后端分离架构中集成AI接口,技术本身并不复杂——无非是封装一层API、加几个中间件。但“优雅”与否,取决于你的设计态度。
是把AI当作一个临时插件随便糊上去,还是把它当作系统的一等公民精心设计?是让前端直接调用一切,还是建立清晰的边界和职责划分?是出了问题再救火,还是提前想好降级和容错?
优雅的集成,意味着你的系统今天可以轻松替换AI供应商,明天可以无缝升级模型版本,后天可以扛住十倍流量而不崩溃。它不炫技,但处处体现着对未来的考虑和对用户的负责。
正如前文所说,前后端分离架构本身就是为这种“可替换性”而生的。把AI接口当作一个普通的微服务对待,给它配好认证、限流、缓存、监控,它就能稳稳当当地在你的系统里发光发热。
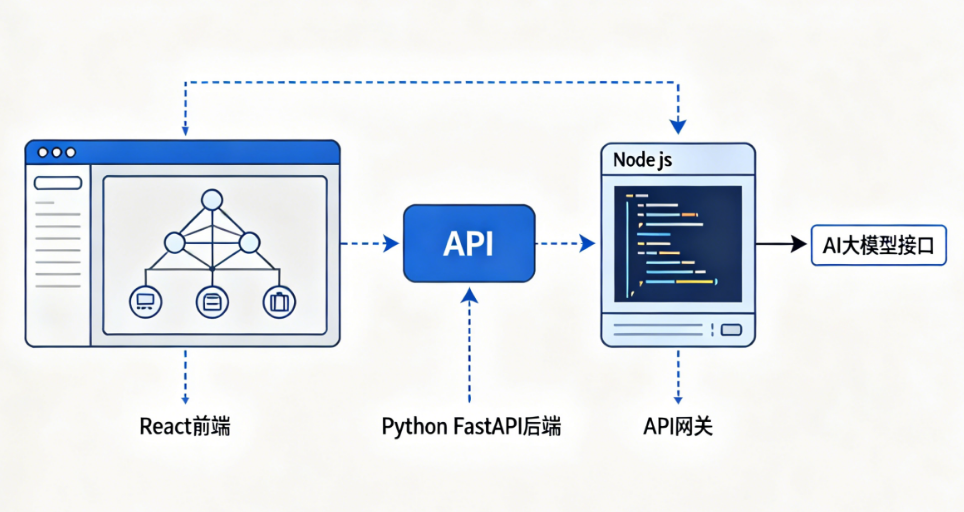
如果你正在规划一个需要集成AI接口的项目——无论是智能客服、AI写作工具还是图像生成应用——却苦于找不到真正懂架构、懂安全、懂性能优化的专业团队,那么一品威客网可以帮你高效匹配优质的技术服务商。
1. 发布任务需求
登录一品威客网,点击“发布需求”,选择“软件开发/AI应用开发”分类。务必把你的需求写清楚:项目类型、预期用户规模、需要集成的AI能力(文本/图像/语音/多模态)、预算范围、技术要求(如必须使用前后端分离架构)。建议特别注明:“希望服务商提供完整的API设计方案和安全防护策略。”发布后通常2小时内就会有多家专业开发团队投标,提供初步方案和案例参考。
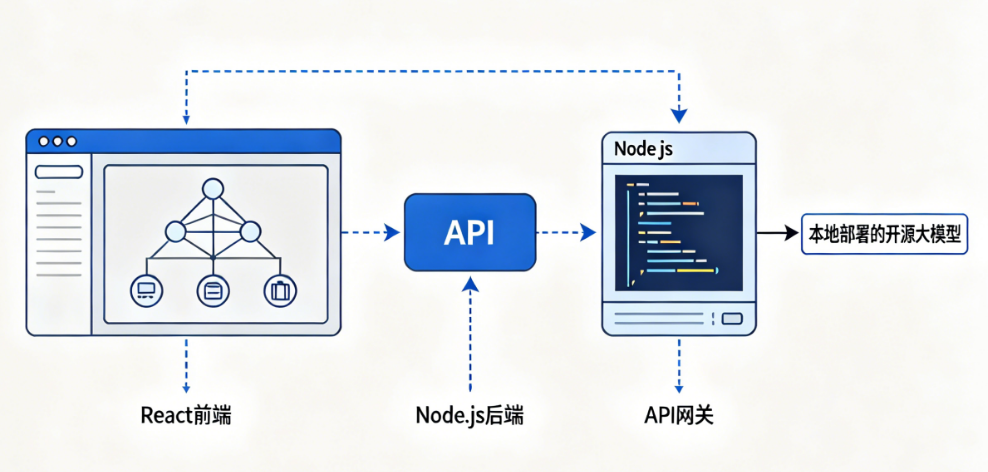
2. 人才大厅找人才
在“人才大厅”,筛选“高级/专家”级别服务商,重点查看他们的商铺案例——有没有做过同类AI项目?案例中是否体现了架构设计能力?代码质量如何?用户评价怎样?真正懂前后端分离的团队,会在案例中展示他们的API设计文档、系统架构图和性能优化成果。
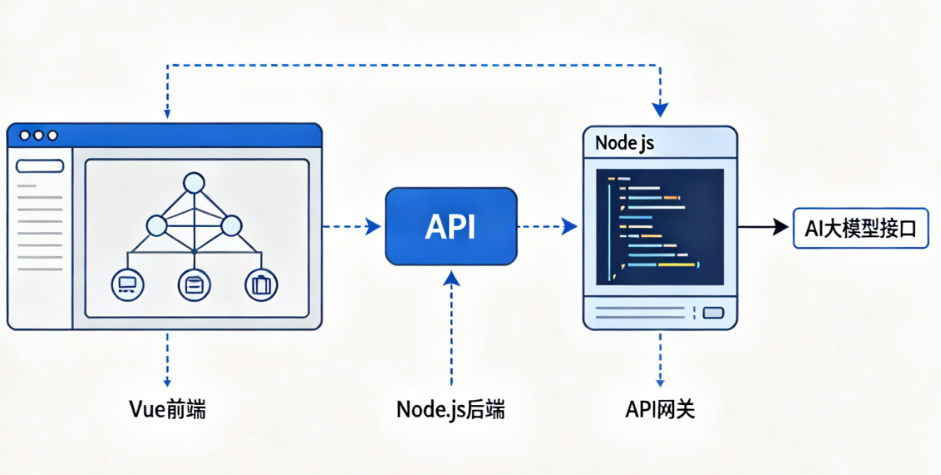
3. 商铺案例参考
在服务商的商铺里,留意他们的技术栈描述。是否熟悉主流AI接口(OpenAI、文心、通义等)?有没有高并发系统设计经验?能否处理模型切换、限流控制、数据缓存等进阶需求?真正专业的团队,会主动和你探讨业务场景、技术选型、潜在风险,而不是简单地“你说什么我做什么”。
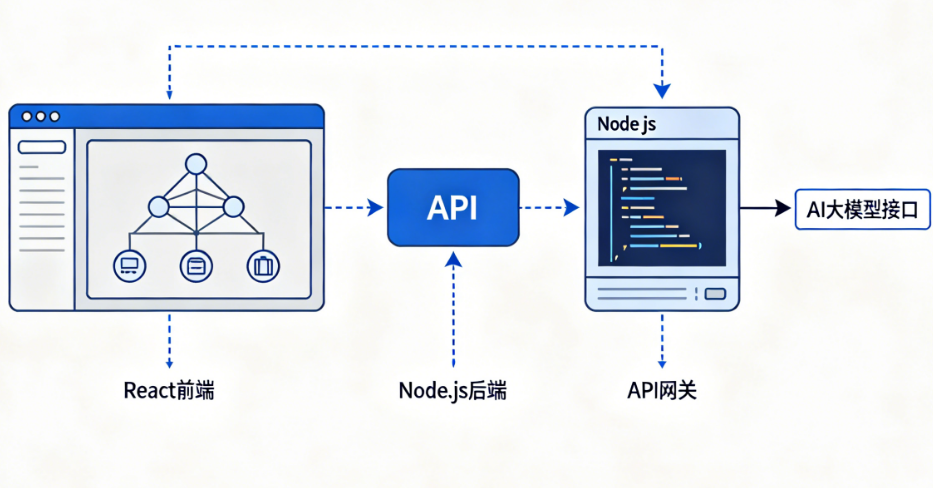
4. 雇主攻略学习
一品威客平台的“雇主攻略”板块汇集了大量真实交易经验和避坑指南。你可以学习如何撰写技术需求文档、如何评估开发方案、如何分阶段验收交付。尤其是关于“AI项目常见坑点”的分享,值得新用户仔细研读——比如API密钥泄露、模型选型失误、成本预估不足等,都是前人用真金白银换来的教训。
从AI接口集成到完整产品落地,找到一个懂技术、懂架构、懂安全的合作伙伴,你的项目就成功了一半。

交易额: 10.34万元
企业 |上海市 |上海市 |普陀区
交易额: 9.62万元
企业 |山东省 |烟台市 |芝罘区
交易额: 7.68万元
企业 |山东省 |德州市 |庆云县
交易额: 6.37万元
企业 |河北省 |石家庄市 |裕华区
成为一品威客服务商,百万订单等您来有奖注册中

价格是多少?怎样找到合适的人才?
¥800 已有0人投标
¥10000 已有2人投标
¥3000 已有8人投标
¥50000 已有1人投标
¥50000 已有0人投标
¥50000 已有0人投标
¥5000 已有8人投标
¥1200 已有0人投标








 企业QQ
企业QQ
 智能客服
智能客服





