 请求处理中...
请求处理中...
请求处理中...
请求处理中...
引言
2026年的移动端AI部署,早已不是“能不能跑起来”的问题,而是“在同样的算力预算下,谁能跑得更快、更准、更省电”。
过去两年,我在三个不同的移动端项目里反复折腾过MobileNet V3和ShuffleNet V2——从Android手机到树莓派,从实时视频流到离线图像分类。一个深刻的体会是:这两兄弟的纸上参数打得有来有回,但真到了具体的硬件上,差距往往藏在那些论文不会告诉你的细节里。
MobileNet V3继承了谷歌家族的一贯风格:结构精致,有神经架构搜索(NAS)加持,集成了squeeze-and-excitation模块和hard-swish激活函数,在CPU和GPU上都有不错的表现 。ShuffleNet V2则走了另一条路:它的设计原则直接源于对“内存访问成本”(MAC)和“并行度”的实测分析,用通道混洗和分组卷积把效率压到极致 。
今天这篇指南,我不打算复述论文里的公式和表格,而是从4个真正影响部署决策的关键指标入手,结合实测数据,给出3类典型场景的选型建议。无论你是正在为App选型的移动端工程师,还是想优化模型性能的算法同学,这份指南都能帮你少踩几个坑。
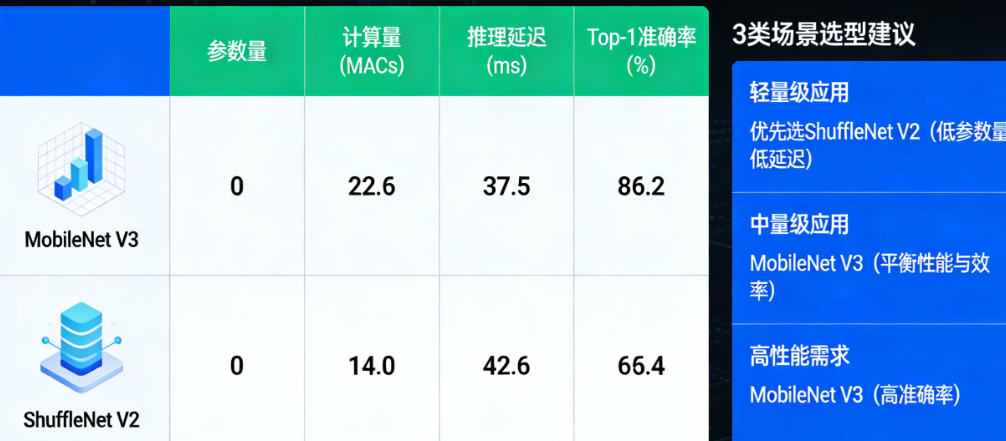
四项关键指标:不止看FLOPs
很多人在选型时只盯着FLOPs(浮点运算次数),觉得这个数越小模型就越快。这是个常见的误区。FLOPs衡量的是计算量,但真正的推理延迟,取决于你的硬件怎么执行这些计算。
指标一:参数量与模型体积
这是最直观的指标,直接决定你的App安装包会变大多少,以及模型加载进内存要占多少空间。
MobileNet V3系列:
MobileNetV3-Small:约 1.53M 参数
MobileNetV3-Large:约 4.21M 参数 ,也有资料显示Large 1.0版本为5.4M参数
ShuffleNet V2系列:
ShuffleNetV2_x1.0:约 1.26M 参数
ShuffleNetV2+ Medium:约 5.6M 参数
ShuffleNetV2+ Large:约 6.7M 参数
单纯看参数,ShuffleNet V2的标准版本比MobileNetV3-Small还要轻量。但要注意,ShuffleNet V2+系列为了追求更高精度,参数量已经超过了MobileNetV3-Large。选型时要看清具体是哪个子版本。
指标二:FLOPs与计算密度
FLOPs是理论计算量,代表模型做一次推理需要多少次乘加运算。
MobileNet V3在FLOPs控制上做得极其出色:
MobileNetV3-Small:仅 61.46M FLOPs
MobileNetV3-Large:约 233.57M FLOPs ,也有资料显示219M MACs
ShuffleNet V2的FLOPs则根据不同缩放系数变化:
ShuffleNetV2_x1.0:约 151.69M FLOPs
ShuffleNetV2+ Small:156M FLOPs
ShuffleNetV2+ Medium:222M FLOPs
ShuffleNetV2+ Large:360M FLOPs
从这个维度看,MobileNetV3-Small在极致低算力场景下有明显优势,而ShuffleNet V2+系列在中等算力区间与MobileNetV3-Large正面竞争。

指标三:推理延迟——最真实的性能标尺
这是所有指标里最“诚实”的一个。FLOPs再低,如果你的硬件不支持某些算子的加速,实际跑起来还是会慢。
CPU延迟对比:
在Google Pixel手机上,MobileNetV3-Large的TFLite延迟约为 51-61ms
MobileNetV3-Small在联发科Genio 420上的CPU延迟约为 6.46ms(8线程)
在树莓派4上,MobileNetV3 Large跑到了 89ms 每帧,这个数字决定了它只能到11FPS,勉强算“可用”
GPU/NPU加速后的差异:
MobileNetV3-Large在GPU上可降至 9.5ms(MACE框架)
在支持NPU的设备上,MobileNetV3-Small的量化版本可低至 0.59-0.82ms(联发科Genio平台)
这里有一个关键洞察:MobileNetV3对硬件加速的支持更好。它的算子设计考虑了CPU、GPU、NPU的通用性,而ShuffleNet V2的分组卷积在某些低端DSP上可能无法完全发挥性能。
指标四:精度——最后的那几个百分点
精度是最终的价值标尺。模型再快,不准就没意义。
ImageNet Top-1准确率:
MobileNetV3-Large:约 75.0%-75.2%
MobileNetV3-Small:约 67.4%
ShuffleNetV2_x1.0:数据较少,但参考相关研究,在类似量级上与MobileNetV3互有胜负
ShuffleNetV2+ Large:约 77.1%(根据公开数据推算)
在其他数据集上的表现:
在CIFAR-10上,MobileNetV3-Small可达 95.49%
在医学图像分类任务中,MobileNetV3和ShuffleNetV2都能通过迁移学习获得 3-8% 的精度提升
一个有意思的发现:ShuffleNetV2经过改进后,在无人机声学探测任务上达到 95.69% 的准确率,同时参数量和计算量分别下降96.4%和97.8% 。这说明ShuffleNetV2的架构有很强的可塑性,针对特定任务优化后能释放更大潜力。
三类场景选型建议
基于以上四个指标,我把移动端部署场景分为三类,分别给出选型建议。
场景一:极致轻量级——内存<100MB,CPU为主,无NPU加速
典型设备:老旧Android手机、低端IoT设备、树莓派3/4
选型结论:优先选择 MobileNetV3-Small
在这个档位,MobileNetV3-Small的61M FLOPs和1.53M参数是无可争议的优势 。它的推理延迟在树莓派4上虽然到不了60fps,但至少能跑出可用的帧率 。ShuffleNetV2_x1.0虽然参数更少,但151M FLOPs意味着计算量是MobileNetV3-Small的两倍多,在纯CPU环境下会慢不少。
实战建议:
一定要用TFLite格式,开启动态范围量化,模型体积能再压缩一半以上
设置线程数为CPU核心数,通常4线程效果最好
输入分辨率可以考虑降到160x160,精度损失有限但速度提升明显
场景二:性能均衡型——有基础NPU或GPU,追求精度与速度平衡
典型设备:中高端Android手机(骁龙8系/天玑9系)、iPhone 12及以上、树莓派5
选型结论:ShuffleNetV2+ Medium 与 MobileNetV3-Large 正面PK,看具体算子支持
两者的FLOPs都在220M左右 ,参数量也相近。关键在于你的目标硬件对谁更友好。
如果目标设备是高通/联发科手机:MobileNetV3-Large通常更稳妥,因为这些平台的神经网络SDK对MobileNet的深度可分离卷积优化得更成熟
如果目标设备是自研NPU或FPGA:ShuffleNetV2+ Medium可能更有潜力,它的分组卷积和通道混洗在定制硬件上可以做到极致优化
如果目标设备是苹果A系列芯片:建议用CoreML工具实测,两个模型都跑一遍,因为苹果的神经引擎对某些算子有特殊优化
实战建议:
开启全整数量化,用代表性数据集校准,速度能再提升30%-50%
考虑用知识蒸馏,用更大的模型做教师,提升轻量级学生的精度
实测发现,MobileNetV3在GPU上的加速效果通常优于ShuffleNetV2
场景三:高精度需求型——可接受较大模型,追求最高准确率
典型设备:旗舰手机、平板电脑、边缘计算盒子(NVIDIA Jetson系列)
选型结论:ShuffleNetV2+ Large 或 MobileNetV3-Large 1.25x
当对精度的要求压倒一切时,两个系列都有放大版可供选择。ShuffleNetV2+ Large的FLOPs达到360M,参数6.7M ,而MobileNetV3也可以通过宽度乘子(1.25x)放大到相近规模。
实战建议:
混合精度推理:对关键层保留FP16,次要层用INT8,在精度和速度间取折中
考虑用RepViT这类混合架构,它在iPhone 12上做到了0.9ms延迟和80.3%精度,已经超越传统CNN
如果对延迟不敏感,可以上EfficientNetV2-S,它的精度更高但计算量也大一个数量级
一个重要的提醒:在这个档位,不要只看模型本身。预处理流水线(图像解码、缩放、归一化)和后处理逻辑可能占据30%以上的总耗时。把这些也优化到位,才能真正榨干硬件性能。
常见问答
Q1:MobileNetV3和ShuffleNetV2,哪个更容易部署?
A:MobileNetV3的算子更“标准”,TensorFlow Lite、PyTorch Mobile、CoreML、TFLite都对它有开箱即用的支持。ShuffleNetV2的分组卷积在某些老版本部署框架里可能遇到算子缺失的问题,需要手动实现或转换。如果你是新手,建议从MobileNetV3起步。
Q2:量化到底选动态范围还是全整型?
A:一个经验法则:动态范围量化保精度,全整数量化保速度。动态范围量化几乎不掉点(0.3%以内),模型缩小到1/4,速度提升2-3倍 。全整数量化可能掉1-2个点,但速度能再翻倍。建议先用动态范围,如果速度还不够再尝试全整型。
Q3:为什么我的模型跑起来比论文里慢很多?
A:大概率卡在内存访问上。ShuffleNetV2的设计原则里专门强调了“内存访问成本”(MAC)——分组卷积虽然FLOPs低,但如果分组太多,数据在内存里搬来搬去反而更慢。实测发现,在某些ARM CPU上,分组数g=2或3时效率最高,g=8时反而可能更慢。
Q4:两个模型都试了,还是达不到目标帧率,怎么办?
A:三个锦囊:1)降分辨率,224x224降到192x192甚至160x160,速度立竿见影;2)裁剪通道,用NetAdapt之类的工具自动搜索每层的最佳宽度;3)换硬件,如果软件优化已经到头,可能是时候考虑带NPU的芯片了。
总结
MobileNetV3和ShuffleNetV2的较量,本质上是两种设计哲学的对决:前者是“用NAS搜索出最优结构,再手工调优”,后者是“从硬件实测原则出发,反向设计网络”。到了2026年,两者都已经进化出庞大的家族系列,覆盖从极致轻量到高精度的全档位。
选型时记住四句话:
看硬件:CPU为主选MobileNetV3-Small,有NPU可选ShuffleNetV2
看精度:两个系列都有放大版,ShuffleNetV2+ Large略占优
看算子:MobileNetV3兼容性更好,ShuffleNetV2需确认部署框架支持
实测为王:所有指标都是参考,跑在你的目标设备上才是最终答案
以上是MobileNetV3 vs ShuffleNetV2的4项关键指标与3类场景选型建议。你可以保存这份指南,在下个移动端项目选型时对照参考。不妨用两个模型在你的目标设备上跑一遍实测,感受理论数据和真实延迟之间的差距。你觉得哪个指标对你启发最大?欢迎在评论区分享你的经验。
一品威客:让专业的人做专业的事
如果你正在寻找靠谱的移动端AI部署人才,或者希望将自己的模型优化能力变现,一品威客网是你的不二选择。作为国内领先的创意服务众包平台,一品威客汇聚了超过百万的专业服务商,提供涵盖移动端模型转换、性能优化、TFLite/CoreML部署、NPU适配等全品类的技术服务。
任务大厅:发布需求,坐等应征
无论你需要将MobileNetV3部署到Android端,还是要优化ShuffleNetV2在树莓派上的推理速度,只需在任务大厅发布详细需求,百万服务商将主动接单。你可以在线比稿、比较案例、沟通细节,找到最适合项目的合作伙伴。
人才大厅:主动搜索,精准对接
如果你想直接寻找移动端AI领域的大牛,人才大厅提供了强大的筛选功能。你可以按技术栈(TFLite/CoreML/ONNX)、项目经验(模型量化/算子优化)、报价等维度筛选,一键雇佣。
每个服务商都有自己的服务大厅和商铺,展示历史案例、客户评价和服务特长。在正式合作前,花几分钟浏览他们的商铺,看看过往的移动端AI项目案例,能帮你做出更明智的决定。
想了解如何评估模型部署效果?想知道不同芯片平台的性能差异?雇主攻略栏目汇集了千万雇主的实战经验。加入V客优享,还能享受专属任务推送、交易保障、工作坊培训等增值服务,真正“改变你的工作方式”。
一品商城:标准化产品,快速交付
对于需求明确、预算固定的标准化服务(如TFLite模型转换、量化脚本开发),可以直接在一品商城下单,享受明码标价、快速交付的便捷体验。
2026年,让专业的人做专业的事。无论你是需求方还是服务方,一品威客都为你准备好了工具箱。


价格是多少?怎样找到合适的人才?
¥100 已有0人投标
¥5000 已有1人投标
¥30000 已有0人投标
¥6000 已有0人投标
¥5000 已有3人投标
¥1000 已有1人投标
¥5000 已有0人投标
¥50000 已有0人投标








 企业QQ
企业QQ
 智能客服
智能客服





