 请求处理中...
请求处理中...
请求处理中...
请求处理中...
引言
“我到底该租云GPU还是自己买一台?”这是过去两年我在社群里被问到最多的问题,没有之一。
上周一位做AI应用创业的朋友给我算了一笔账:他计划用三个月时间微调一个法律咨询模型,预算三万块。租云GPU的话,每小时几十块钱,看起来挺便宜;但如果自己买张卡,三个月后还能剩张显卡。他纠结得整晚睡不着——选错了,要么钱白花了,要么进度被卡住。
这不是个例。微调预算这件事,说简单也简单,说复杂也复杂。简单的是,你只需要知道“每小时多少钱”;复杂的是,当你把数据准备时间、试错次数、部署成本、电费折旧全算进去,两个选项的真实差距往往藏在那些看不见的地方。
今天这篇文章,我结合2026年最新的云服务商定价和硬件市场行情,从GPU按小时计费怎么算开始,把云服务和本地部署的成本构成拆成5个维度,给你一套可复用的决策框架。无论你是个人开发者还是企业决策者,这篇文章都能帮你把预算算清楚、把钱花明白。
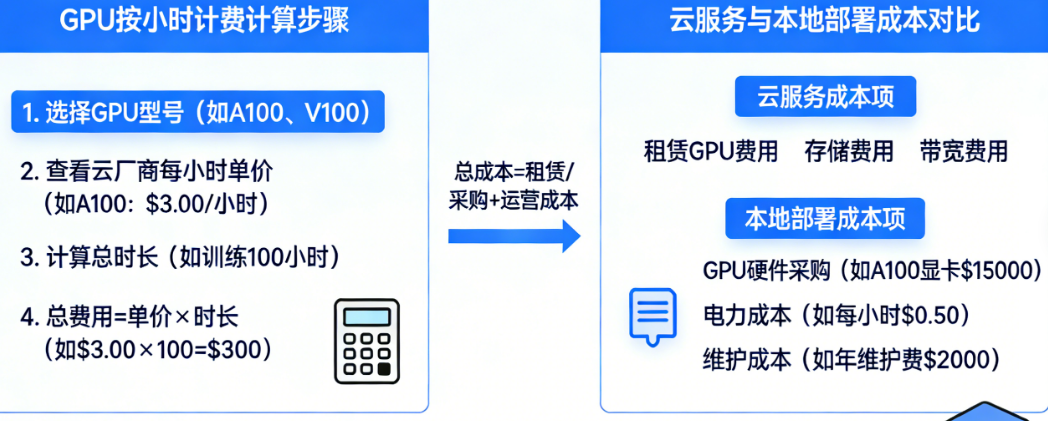
一、GPU按小时计费怎么算?2026年最新价格拆解
1.1 云GPU的三种计费模式
在讨论具体价格之前,我们需要先搞清楚云GPU的计费逻辑。目前主流云厂商都提供三种计费方式:
按量付费(按小时/按秒):这是最灵活的模式,你用多少付多少,随时创建随时释放。适合临时测试、短期项目、或者不确定需要跑多久的实验。缺点是单价最高,长期使用不划算。
包年包月(预付费):一次性付一个月或一年的费用,单价通常是按量付费的5-7折。适合业务稳定、需要长期运行的场景。
抢占式实例:云厂商把闲置资源低价放出,价格可能是按量付费的1-3折,但随时可能被回收。适合容错性高的离线任务,比如数据处理、模型评估,但千万别用来跑核心训练——万一跑到一半被回收,前功尽弃。
1.2 2026年主流云GPU价格参考
基于2026年最新市场数据,我整理了几款主流GPU的按小时计费价格,你可以作为预算参考:
入门级推理与轻量微调:
T4(16G显存):约1.87元/小时,月付约1681元
适合场景:7B以下模型微调、轻量推理、图像识别
中端主力:
A10(24G显存):约3.56元/小时,月付约3204元
V100(16G显存):约4.24元/小时,月付约3817元
适合场景:7B-13B模型微调、中型推理任务
大模型专用:
L20(48G显存):约7.69元/小时,月付约6929元
A100(80G显存):约25-35元/小时(不同规格差异较大)
适合场景:30B-70B大模型微调、全参数微调
多卡集群:
2卡L20:约13858元/月
4卡L20:约27717元/月
8卡L20:约55434元/月
一个容易被忽略的细节:云厂商的定价通常包含基础实例费(CPU+内存)和GPU附加费。有些低价广告只标了GPU费,点进去才发现CPU内存配置很低,跑起来可能卡在数据加载上。选型时一定要看完整配置。
1.3 按Token计费的新模式
除了按小时计费,2026年还有一个值得关注的新趋势:按Token计费。阿里云百炼平台、百度千帆等平台都推出了这种模式。
以百度千帆为例,ERNIE-Speed-8K模型的SFT训练,按量付费仅0.02元/千tokens。阿里云的wan2.6视频生成模型微调,训练价格0.08美元/千Token。
这种模式对开发者非常友好——你不用关心跑了多少小时,只需要关注实际处理的Token量。对于数据量较小、训练轮次不多的任务,可能比按小时计费更划算。
计算公式:训练费用 = 训练Tokens总量 × 训练单价
举个栗子:微调一个模型,训练集2万条数据,每条平均500Token,训练3个epoch,总Token量=2万×500×3=3000万Token,按0.02元/千Token计算,总费用=3000万÷1000×0.02=600元。
这种模式下,你不需要纠结“租什么卡跑得快”,平台会自动调度算力,你只需要为实际消耗的算力付费。
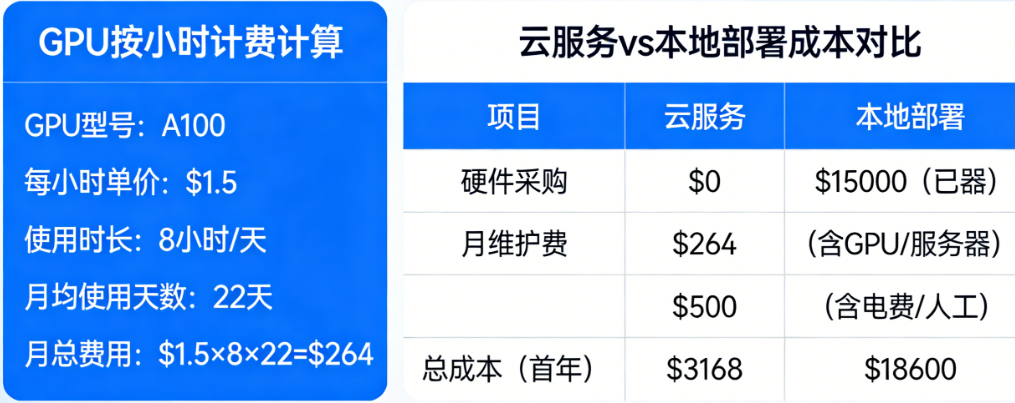
二、本地部署:自己买卡到底要花多少钱?
2.1 硬件采购成本(2026年2月最新行情)
2026年初的GPU市场经历了一波涨价,现在入手需要比去年多掏不少钱。
消费级显卡:
RTX 5060 Ti 16GB:约500美元(约3600元人民币)
RTX 5070 Ti 16GB:约1000美元(约7200元)
RTX 3090 24GB(二手):约950美元(约6800元)
RTX 4090 24GB:约2400美元(约1.7万元)
专业级显卡:
RTX 6000 Ada 48GB:约5300美元(约3.8万元)
RTX A6000 48GB:约4500美元(约3.2万元)
RTX Pro 6000 96GB:约8500美元(约6.1万元)
一个扎心的事实:从2025年11月到2026年2月,RTX 3090二手价涨了26.7%,RTX 5080涨了42.9%,RTX 5090涨了40%。如果你半年前犹豫没买,现在要多花好几千。
2.2 配套硬件成本
显卡只是第一步,你还得配齐整套机器:
主机配置:CPU(至少8核)、主板(支持多卡)、内存(至少64GB)、电源(至少1000W)、机箱、散热,约5000-8000元
NVMe硬盘:模型权重动辄几十GB,2TB NVMe约1000-1500元
显示器/键鼠:如果你没备用的,再加1000元
2.3 隐性成本:电费、散热、维护
这是新手最容易忽略的部分。
电费:一张RTX 4090满载功耗约450W,一天跑10小时就是4.5度电。按0.6元/度算,一个月电费约80元。如果你跑8卡集群,一个月电费轻松过千。
散热:高性能显卡发热量惊人,夏天不开空调可能热到死机。这部分成本很难量化,但真实存在。
维护成本:硬件故障、驱动兼容性问题、系统重装,这些都是时间成本。对于团队来说,还需要有人负责服务器运维。
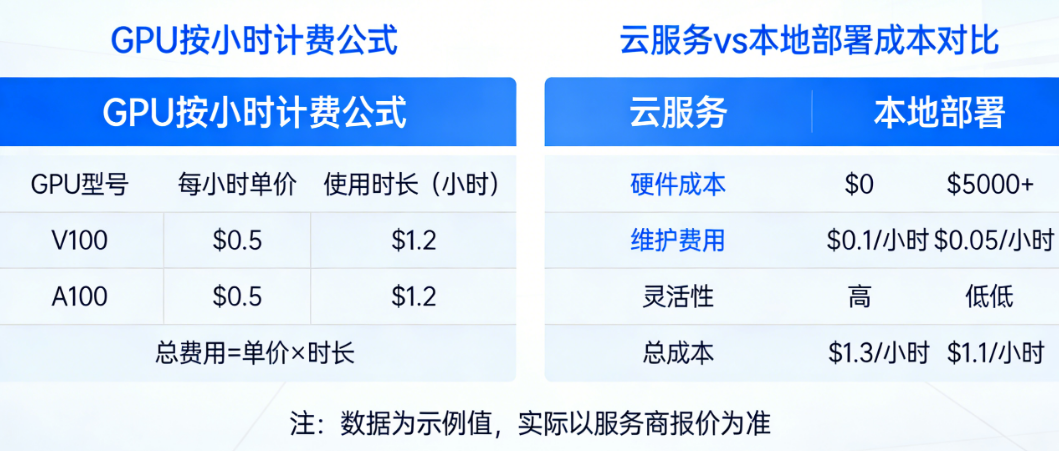
三、云服务 vs 本地部署:5个维度的全面对比
3.1 成本结构:资本支出 vs 运营支出
这是最根本的差异。
云服务是运营支出(OpEx):没有前期投入,按月/按小时付费,用多少花多少。现金流压力小,适合初创团队和短期项目。
本地部署是资本支出(CapEx):前期一次性投入几万块,然后逐年折旧。长期看,如果利用率高,单均成本可能更低;但如果利用率低,钱就白花了。
一个简单的决策公式:假设你每天跑满24小时,连续跑N个月,云服务的总成本=月租金×N,本地部署的总成本=硬件费用+电费。当N超过某个阈值(通常是6-12个月),本地部署开始划算。
3.2 弹性与 scalability
云服务:今天用单卡,明天用8卡,后天释放掉,完全按需伸缩。项目结束了,一分钱不用再花。
本地部署:买了8卡,就只能用8卡;想升级得再买新卡;项目结束了,卡闲置在那里,或者转手卖掉(还要折价)。
3.3 技术门槛与运维负担
云服务:实例开起来就能用,驱动、环境都配好了。出了问题,提工单就行。
本地部署:你得自己装驱动、配CUDA、调网络、搞散热。一旦出问题(比如驱动版本不兼容),可能卡你好几天。网上有个段子:本地部署的AI工程师,30%的时间在调模型,70%的时间在修环境。
3.4 数据安全与隐私
云服务:数据要上传到云端,虽然厂商有加密和隔离,但对于金融、医疗、法律等敏感领域,合规要求可能不允许。
本地部署:数据全程在内网,物理隔离,安全性完全自己掌控。这也是很多大厂和政府部门坚持本地部署的核心原因。
3.5 团队协作效率
这是2026年出现的一个新视角。传统观念里,本地部署意味着“每人一张卡”。但现在的技术已经可以做到:一张卡服务整个团队。
用vLLM配合continuous batching技术,一张24GB显存的RTX 3090可以同时服务8-16个开发者,GPU平均利用率从5%-15%提升到80%以上。这意味着一个5人团队,可能只需要1-2张卡就够了,而不是每人一张。
从经济账看:5人团队每人买一张RTX 4090,硬件投入约8.5万元;如果采用共享GPU服务器模式,一台双卡工作站约3.5万元,再加一台普通PC做跳板机,总投入不到4万元,省下一半以上。
四、怎么选?三种典型场景的决策建议
场景一:个人开发者、学生、初创团队
特点:预算有限,项目不确定,技术栈还在摸索
建议:优先选云服务。用按量付费或抢占式实例,低成本试错。等模型跑通了、业务稳定了,再考虑要不要转包年包月。千万别一上来就买卡——万一项目做不下去,显卡砸手里亏死。
预算参考:
微调7B模型+5000条数据+LoRA:约10-20小时,成本20-40元
微调13B模型+1万条数据+LoRA:约30-50小时,成本100-200元
场景二:中型团队、稳定业务
特点:团队3-10人,有持续微调和推理需求,项目周期6个月以上
建议:混合模式。核心训练任务用包年包月云实例,享受折扣价;日常推理和开发测试用共享本地GPU服务器,一张卡服务全队。这样既保证弹性,又控制长期成本。
预算参考:
云上:L20包年约6.6万元(年付8折)
本地:双卡工作站约4万元(分摊到3年折旧,月均1100元)
电费+维护:月均500元
场景三:大厂、研究机构、敏感行业
特点:数据敏感,合规要求高,长期大规模训练
建议:本地部署为主,云为辅。核心数据和模型训练放在本地集群,完全掌控;临时扩容、突发需求用云上的抢占式实例补充。数据绝对不能出内网,这是底线。
预算参考:
8卡A100集群:硬件投入约80-100万元
机房/散热/电费:年运营成本约15-20万元
运维团队:至少1人专职
常见问答
Q1:按小时计费,是不是用得越久越划算?
A:不一定。按小时计费的单价是固定的,用得越久总费用越高。真正划算的是包年包月——如果你能确定未来6-12个月都要用,包年能省20%-45%。如果你只是临时跑几天,按小时更灵活。
Q2:我该买RTX 4090还是租A100?
A:看你跑什么模型。如果是13B以下,4090足够;如果是70B大模型,A100的80G显存更有优势。从成本看,4090买断约1.7万,A100租一个月约1.8万(按35元/小时×24小时×30天计算)——一年的话,租比买贵很多,但你要承担硬件维护和数据安全的成本。
Q3:数据量很小,是不是可以不用GPU?
A:不行。微调必须用GPU,CPU跑不动。但你可以用云上的低端卡,比如T4,一小时不到2块钱,几百条数据可能几小时就跑完了。
Q4:共享GPU服务器靠谱吗?会不会互相影响?
A:2026年的技术已经很成熟了。用vLLM的continuous batching,可以动态调度请求,多个用户同时用几乎感觉不到排队。只要配置好权限和限流,体验接近每人一张卡,成本却低得多。
Q5:电费到底怎么算?
A:一张RTX 4090满载约450W,一天跑10小时就是4.5度电。按居民电价0.6元/度算,一个月约80元。如果是8卡集群,一个月电费轻松过千。商业电价更贵,可能翻倍。
Q6:云上训练中途取消,会收费吗?
A:会。只要你用了资源,哪怕中途取消,已产生的费用照收不误。只有因为云厂商自身原因导致的中断,才可能不收费。所以别指望“先跑跑看,不行就取消”来省钱——试错成本是真实存在的。
总结
微调预算这件事,核心不是“云便宜还是本地便宜”,而是“你的业务模式适合哪种付费方式”。
云服务:灵活、低门槛、无维护负担,适合探索期和短期项目。按小时计费让你精确控制成本,按Token计费让你只为实际消耗付费。
本地部署:前期投入高、长期成本低、数据安全可控,适合稳定业务和敏感场景。2026年的共享GPU技术,让团队协作成本大幅降低。
真正聪明的做法是:从云开始,用共享技术降本,等业务稳定再考虑本地。别让硬件选择成为你探索AI的绊脚石——先跑起来,再优化成本。
以上是微调预算的完整拆解。你可以保存这份指南,在下个项目启动前对照算账。尝试用按量付费跑一个小模型,记录实际时长和费用,感受云计算的灵活;再算算如果自己买卡,多久能回本。你觉得哪个维度对你启发最大?欢迎在评论区分享你的经验。
一品威客:让专业的人做专业的事
如果你正在寻找靠谱的AI微调人才,或者希望将自己的模型训练能力变现,一品威客网是你的不二选择。作为国内领先的创意服务众包平台,一品威客汇聚了超过百万的专业服务商,提供涵盖大模型微调、数据准备、GPU算力租赁、模型部署等全品类的技术服务。
任务大厅:发布需求,坐等应征
无论你需要微调一个法律咨询模型,还是需要帮你算清预算、选型硬件,只需在任务大厅发布详细需求,百万服务商将主动接单。你可以在线比稿、比较案例、沟通细节,找到最适合项目的合作伙伴。
人才大厅:主动搜索,精准对接
如果你想直接寻找AI领域的大牛,人才大厅提供了强大的筛选功能。你可以按技术栈(PyTorch/LoRA)、项目经验(大模型微调/部署优化)、报价等维度筛选,一键雇佣。
每个服务商都有自己的服务大厅和商铺,展示历史案例、客户评价和服务特长。在正式合作前,花几分钟浏览他们的商铺,看看过往的AI项目案例,能帮你做出更明智的决定。
想了解如何评估微调效果?想知道不同预算下该怎么选型?雇主攻略栏目汇集了千万雇主的实战经验。加入V客优享,还能享受专属任务推送、交易保障、工作坊培训等增值服务,真正“改变你的工作方式”。
一品商城:标准化产品,快速交付
对于需求明确、预算固定的标准化服务(如微调脚本开发、云实例配置指导),可以直接在一品商城下单,享受明码标价、快速交付的便捷体验。
2026年,让专业的人做专业的事。无论你是需求方还是服务方,一品威客都为你准备好了工具箱。


价格是多少?怎样找到合适的人才?
¥20000 已有15人投标
¥3000 已有0人投标
¥10000 已有0人投标
¥50000 已有1人投标
¥100000 已有0人投标
¥5000 已有3人投标
¥5000 已有0人投标
¥5000 已有1人投标








 企业QQ
企业QQ
 智能客服
智能客服





