 请求处理中...
请求处理中...
请求处理中...
请求处理中...
引言
痛点场景:当你满怀期待地开发或部署了一个智能体,却发现自己根本不知道它究竟表现如何——它时而聪明伶俐,时而答非所问;在简单场景下游刃有余,遇到复杂任务却频频出错。更令人沮丧的是,你无法用数据向团队或客户证明这个智能体的真实水平,每次演示都像一场赌博,心里完全没有底。
核心价值:本文将为你建立一套完整的智能体性能评估体系,从核心指标到测试方法,让你能够像专业测试工程师一样,客观、量化地衡量智能体的真实能力,为迭代优化提供坚实的数据支撑。
提纲预览:我们将首先梳理智能体评估的六大核心指标,接着讲解从单元测试到场景模拟的完整测试流程,最后通过常见问题解答帮助你避开评估中的各种“坑”。
前置准备
在开始评估智能体之前,你需要准备好三样东西。第一是测试数据集,这是评估的基石,建议准备至少三类数据:标准场景数据(约占70%)、边界场景数据(约占20%)和异常输入数据(约占10%)。第二是评估环境,包括独立于开发环境的测试服务器、日志记录系统和结果对比工具。第三是评估标准文档,明确定义每个指标的计算方式和及格线,避免在评估过程中因标准模糊而产生争议。
核心步骤
步骤1:明确智能体的能力边界与评估维度
不同类型的智能体,评估的侧重点截然不同。对话型智能体要重点关注响应准确率和对话连贯性,任务执行型智能体要考察流程完成率和执行效率,而决策推荐型智能体则需要用点击率、转化率等业务指标来衡量。在开始任何测试之前,你首先要问自己一个问题:这个智能体被设计出来,到底要解决什么问题?把这个问题的答案写下来,围绕它来确定评估的核心维度。比如一个客服智能体,它的核心价值是解决用户问题、减少人工介入,那么“问题解决率”和“转人工率”就是比“回答字数”或“响应速度”更关键的指标。
步骤2:构建分层测试体系
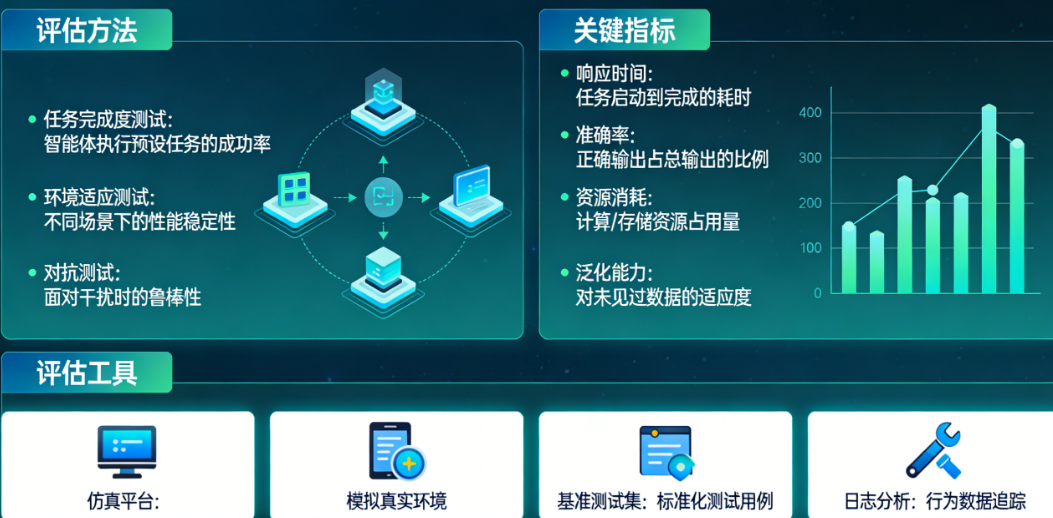
优秀的智能体评估绝不是“跑一遍数据看个分数”这么简单,它需要分层推进。第一层是单元测试,针对智能体的每个独立功能模块进行验证,比如意图识别模块是否准确、信息提取模块是否完整、工具调用模块是否按预期执行。这一层要追求自动化,每次代码变更后都能快速跑一遍。第二层是集成测试,验证各模块协作时的整体表现,重点关注模块间的数据传递是否准确、异常处理机制是否有效。第三层是场景模拟测试,构建完整的用户交互流程,从用户发起请求到智能体给出最终结果,模拟真实使用环境下的各种情况,包括多轮对话、中途打断、信息更正等复杂交互场景。
步骤3:建立核心评估指标体系
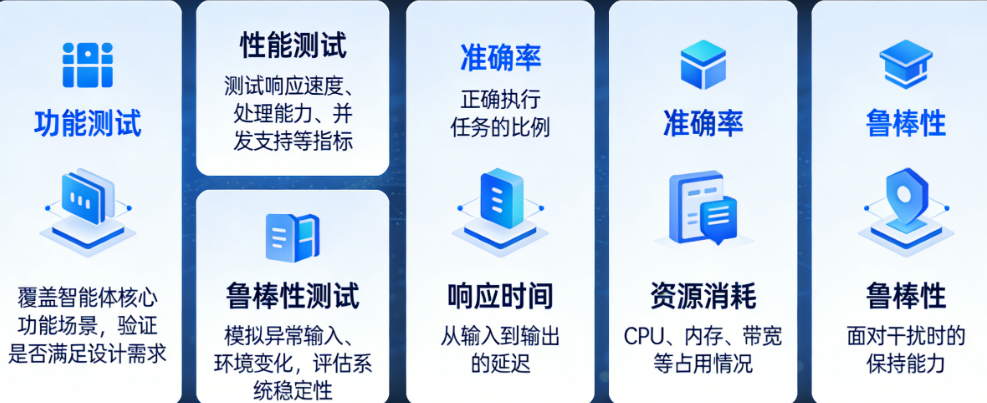
智能体评估需要一套全面的指标体系,我将其归纳为六个维度。准确率是基础中的基础,衡量智能体给出的答案或执行的动作是否正确,但要注意准确率并非越高越好,有时过度追求准确率会导致智能体变得保守、拒绝回答本该能回答的问题。完成率关注的是智能体是否能将任务完整执行到底,比如一个订票智能体,用户说完需求后,它是否完成了从查询、选座到支付的全流程。效率指标包括响应时间和资源消耗,过长的响应时间会严重影响用户体验。鲁棒性考察智能体在面对异常输入、模糊表达、信息缺失等情况时的处理能力,这是区分成熟智能体和原型产品的重要分界线。一致性确保智能体在面对相同或相似的问题时,给出的答案保持稳定,不会出现前后矛盾的情况。用户满意度则需要通过用户反馈、评分机制来收集,这是最贴近真实体验的指标。
步骤4:执行测试并建立对比基准
测试执行阶段最核心的原则是“可复现、可对比”。所有测试输入都应被记录,测试结果应保存原始日志,方便后续追溯分析。建议建立至少三个对比基准:一是与上一版本的对比,用于验证迭代是否带来了真实提升;二是与人工基准的对比,计算智能体在特定任务上达到了人类水平的百分之多少;三是与竞品或行业标准的对比,了解自己在市场中的位置。测试数据量要足够支撑统计显著性,一般来说每个场景至少需要200-300个测试样本。
步骤5:持续监控与迭代优化
智能体评估不是一次性的工作,而应该融入研发流程成为持续性的环节。建议建立自动化的每日巡检机制,用少量核心用例(通常50-100条)快速验证智能体的基础能力是否稳定。每周或每两周进行一次全量回归测试,确保新功能没有破坏原有能力。每次上线前都要完成完整的评估报告,报告中除了数据外,还要包含对失败案例的根因分析,以及针对性的优化计划。

常见问题与避坑指南
问题一:测试数据与真实场景严重脱节。这是最常见的错误,很多团队用自己编写的“理想化”数据测试,结果上线后表现一落千丈。解决方法是从真实用户日志中抽取数据构建测试集,同时定期更新数据,保持测试集与真实场景的同步。
问题二:过度关注单一指标。有些团队只盯着“准确率”一个数字,导致智能体在优化过程中变得“谨小慎微”,大量本该回答的问题被拒绝。正确做法是建立指标体系,设置多个指标的综合考量机制,比如“准确率+覆盖率”的组合更能反映真实能力。
问题三:忽略了多轮对话的评估。很多评估方法只看单轮问答的效果,但智能体真正的价值往往体现在多轮对话中——理解上下文、记住之前的信息、在信息逐步收集中推进任务。评估时必须构建完整的多轮对话测试用例,考察智能体在整个会话过程中的表现。
问题四:测试环境与生产环境差异过大。测试环境中的模型版本、知识库、工具接口与生产环境不一致,导致测试结果失真。解决方案是尽量保持测试环境与生产环境的一致性,或者使用流量回放技术在生产环境进行灰度验证。

进阶技巧与额外提示
要让评估工作事半功倍,可以尝试以下几个进阶方法。引入对抗性测试,专门设计刁钻的、带有误导性的输入来测试智能体的边界能力,比如语义模糊的表达、包含矛盾信息的请求、故意绕弯子的对话方式,这能帮助发现常规测试中难以暴露的问题。建立自动化评估流水线,将测试数据准备、环境部署、测试执行、结果分析、报告生成全流程自动化,每次代码提交都能自动触发,大幅提升评估效率。使用大模型辅助评估,对于开放式问答类智能体,人工评估成本极高,可以利用更强的模型作为“评审员”,对智能体的输出进行打分和评价,虽然不能完全替代人工,但可以作为高效的初筛手段。建立错误案例库,将所有测试中发现的失败案例收集起来,分类标注错误类型,这个案例库既是优化方向的指引,也是回归测试时最重要的验证素材。
总结
智能体性能评估是一项系统工程,从明确评估维度开始,到构建分层测试体系、建立核心指标体系、执行测试并建立基准,最后融入持续监控的研发流程。评估的目的从来不是得到一个好看的分数,而是真实了解智能体的能力边界,为每一次优化提供方向指引。掌握了这套方法,你就能从“凭感觉判断智能体好坏”进阶到“用数据驱动智能体优化”的成熟阶段。接下来,你可以将这些评估方法应用到实际项目中,通过反复实践来打磨属于你自己的评估体系,让每一个智能体的迭代都有据可依。
一品威客任务发布指南
如果你正在寻找专业的智能体开发或评估人才,一品威客平台可以帮你高效对接优质服务商。在任务大厅发布需求时,建议将本文中的评估指标融入任务要求,明确列出需要达到的准确率、完成率、响应时间等量化标准,这样能吸引到真正专业的人才。在人才大厅搜索时,可以重点关注服务商过往案例中是否包含类似的智能体项目经验。服务大厅的商铺案例是很好的参考材料,仔细研究优秀服务商的项目交付记录和质量口碑,能帮助你做出更明智的选择。一品威客还提供威客攻略学习板块,汇集了大量项目管理和需求对接的实战经验。一品商城则可以直接采购成熟的智能体解决方案或评估工具。加入V客优享会员,还能享受专属的项目对接服务和权益保障。一品威客汇聚百万服务商提供文化创意服务,从智能体开发到性能评估,从技术实现到创意设计,一站式的平台资源正在改变传统的工作方式,让你的项目需求找到最合适的解决方案。

交易额: 16.67万元
企业 |山东省 |济南市 |济南市
交易额: 16.09万元
企业 |河北省 |石家庄市 |新华区
交易额: 14.22万元
企业 |北京市 |北京市 |丰台区
交易额: 9.79万元
企业 |浙江省 |宁波市 |鄞州区
成为一品威客服务商,百万订单等您来有奖注册中

价格是多少?怎样找到合适的人才?
¥1000 已有1人投标
¥100 已有0人投标
¥5000 已有1人投标
¥30000 已有0人投标
¥6000 已有0人投标
¥5000 已有3人投标
¥1000 已有1人投标
¥5000 已有0人投标








 企业QQ
企业QQ
 智能客服
智能客服





