 请求处理中...
请求处理中...
请求处理中...
请求处理中...
很多企业在搭建智能客服时,都会卡在一个灵魂拷问上:到底选这两年风头正劲的大模型,还是用已经成熟稳定的传统NLU?有人说大模型是未来,不跟风就落伍了;也有人说传统NLU够用又省钱,别瞎折腾。两边都有道理,反而让人更懵了。别慌,今天这篇文章就是帮你彻底搞清楚这两种技术路线的真实区别。我们不聊玄学,不堆术语,直接从功能、性能、成本、适用场景四个维度下手,掰开揉碎对比一遍。读完你就能拍着桌子说:我知道该选哪个了。
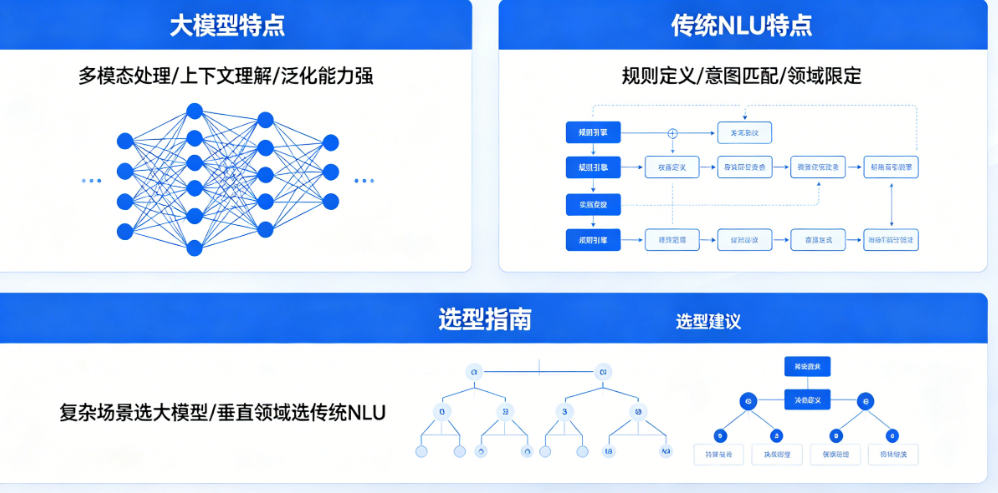
快速对比摘要:一句话先给结论
如果你追求开箱即用、对话自然、能处理开放性问题,预算充足且不介意几秒钟的延迟——大模型更香。如果你的业务场景高度固定、答案标准化、对响应速度和成本极度敏感——传统NLU依然是王者。简单说:大模型像“聪明但话多的大学生”,传统NLU像“快准狠的老会计”。
深度对比分析
一、核心功能对比:听懂人话 vs 说人话
传统NLU的核心能力是意图识别和槽位提取。它会把用户说的一句话拆解成“用户想干嘛”(意图)和“具体信息是什么”(槽位)。比如你说“我要订明天去北京的机票”,传统NLU能精准识别意图=“订票”,槽位={日期=明天,目的地=北京}。它非常擅长这类结构化、可枚举的任务,而且准确率能做到95%以上。但它的短板也很明显:不会聊天。你如果问“明天北京天气怎么样,适合飞吗?”,它就懵了,因为这个问题不在预设意图里。
大模型的核心能力则是自由对话和生成式回答。它不需要你把问题框死在固定的意图里,你甚至可以说“我下周想去北京玩,但又怕下雨,你说我该不该飞过去?”——大模型能理解情绪、推理场景、给出建议式回答。它更“像人”,能处理开放域、非结构化的问题。但反过来,它在精确的槽位提取上反而不如传统NLU稳定(比如容易把“明天”理解成“今天”),而且容易“话多”甚至“胡说”。
小结:要“精准执行指令”,选传统NLU;要“自然交流体验”,选大模型。
二、性能与效果对比:快准狠 vs 慢但全
响应速度:传统NLU是绝对的王者。一个轻量级NLU模型(比如Rasa或基于BERT的小模型)在普通服务器上,单次推理耗时通常在50毫秒以内,用户完全无感知。大模型就差远了,哪怕是7B参数量的量化模型,加上RAG检索,单次回答也要2-5秒;如果用云端闭源大模型(GPT-4级别),加上网络延迟,5-10秒是常态。用户等不了这么久的,尤其是在售后、查订单这类高频场景。
准确率稳定性:在封闭域任务上,传统NLU的意图识别准确率可以稳定在95%-98%,而且可解释性强——错了你知道为什么错(比如缺少训练数据)。大模型在同样的封闭任务上,经过精细微调后能达到90%-95%,但它有个致命问题:不稳定。同样的问题问10次,可能9次对1次跑偏,这种“不可预测性”对客服场景是灾难。
长尾处理能力:这是大模型的王牌。传统NLU对训练集之外的“没见过的问题”基本束手无策,只能走“默认回复”或转人工。大模型即便没见过,也能根据语义理解推测着回答,长尾问题的解决率能从30%直接拉到80%以上。

三、价格与性价比:省钱省心 vs 烧钱换体验
传统NLU的显性成本低。开源方案(Rasa、rasa-like)免费,你需要付出的主要是:标注训练数据的成本(一个人月大概能标5000-10000条)、服务器成本(一台4核8G的云服务器,月费200-300块跑得飞起)。如果你的业务意图在50个以内,整体年成本可以控制在2万以内。
大模型的显性成本高得多。开源自部署方案:需要A10或V100级别显卡,单台服务器月费至少2000-3000块,再加上微调成本(通常需要几千到上万条高质量数据,标注费至少1-2万)。云端API方案:按token计费,一个日活1万的客服场景,月成本轻松破万。整体年成本通常在5万到20万之间。
但别忘了隐性成本:传统NLU每次新增业务意图,都要重新标注、训练、测试、上线,迭代周期以“周”为单位,产品经理掉头发。大模型新增知识只需要更新知识库(RAG),不需要重新训练,迭代成本趋近于零。这个账要算清楚。

四、用户体验与易用性:谁上手更友好?
传统NLU的学习曲线陡。你需要懂一点机器学习概念(意图、实体、槽位、故事),还需要会写训练数据格式(YAML或JSON),调参更是玄学。一个小白团队从零到第一个可用机器人,平均需要2-3周。
大模型(尤其是用RAG框架)的上手门槛低得多。你甚至不需要懂模型原理,只要会写提示词、会整理文档,用LangChain或LlamaIndex搭一个原型可能只需要一天。但注意:原型好用不代表生产好用。到了优化速度、控制幻觉、多轮对话这些环节,大模型的天花板反而更高,需要更专业的工程能力。
适用场景与人群分析
选择传统NLU,如果你……
业务场景高度固定,意图不超过50个,比如“查订单”“改地址”“退换货申请”
对响应速度要求极高(1秒以内),比如电商大促期间的实时查询
预算有限,年技术投入低于3万
团队内部有懂标注和基本机器学习的人
不需要“聊天感”,用户只求快准狠
选择大模型,如果你……
业务场景开放多变,用户问题五花八门,比如售前咨询、产品推荐、使用指导
追求“类人对话体验”,希望客服显得聪明、亲切、不机械
预算相对充足,愿意为体验付费
知识更新频繁(每周都有新活动、新产品),不想反复训练模型
能接受2-5秒的响应延迟,或愿意用异步/排队机制兜底

常见问题
问:能不能大模型+传统NLU一起用?
能,而且这其实是目前的最佳实践。用传统NLU做第一道“快速路由”,识别出高确定性的意图(比如“查物流”)直接走轻量级流程;模糊或复杂问题再交给大模型兜底。这种“混合架构”既保住了速度,又兜住了长尾。
问:我现在的传统NLU系统,能平滑升级到大模型吗?
可以,但别指望“一键升级”。常见路径是:保持原有NLU系统不变,在旁边搭一套大模型RAG服务,用置信度阈值做分流(NLU置信度低于0.6的走大模型)。两套系统并行跑,逐步切流量。
问:大模型的“幻觉”问题在客服场景真的可控吗?
可控,但需要工程手段兜底。强制要求大模型回答时附上检索来源(RAG的引用),并对用户展示“以上信息来自XXX文档”;同时在后端做一层规则过滤,对价格、日期、政策类关键词进行二次校验。这两招能拦住95%以上的幻觉。
最终结论与推荐
别被“大模型”三个字冲昏头脑,也别把传统NLU当成老古董。如果你的客服场景是高频、固定、结构化(比如查物流、改密码、申请发票),老老实实用传统NLU,省钱、省心、还快。如果你的场景是低频、多变、需要理解复杂语义(比如产品选型建议、故障诊断、情感安抚),大模型是不可替代的。最聪明的做法不是二选一,而是混合架构:传统NLU做快车道,大模型做兜底网。预算有限的中小企业,建议从传统NLU起步,把80%的常见问题跑通;大促期间或业务扩张时,再按需引入大模型做“外挂”。
一品威客任务大厅发布需求:找懂“传统NLU+大模型混合架构”的智能客服开发团队
我需要在现有客服系统基础上,搭建一套混合架构智能客服:高频意图(约30个)用传统NLU快速响应(响应时间<200ms),复杂开放问题切换到大模型+RAG兜底(基于Qwen或ChatGLM)。要求服务商具备Rasa或Claude等NLU框架的实际项目经验,以及大模型私有化部署能力。知识库约500份文档,需支持每周自动同步更新。预算4-7万,需提供30天内的可演示Demo。发布路径:一品威客网首页→任务大厅→发布悬赏→选择“AI应用开发”→标题写清楚“混合架构智能客服”。建议同时去“人才大厅”搜索“NLU工程师”或“RAG开发”,查看服务商的“商铺案例参考”里是否有相似案例;新手可以先看“雇主攻略学习”了解验收标准和数据标注规范;预算有限的可以逛逛“一品商城”的轻量级客服SaaS模板;开通“V客优享”会员可享受需求优先推送和平台补贴——改变你的工作方式,一品威客汇聚百万服务商,提供文化创意、AI开发、软件定制等全品类服务。

交易额: 427.32万元
企业 |山东省 |济南市 |历下区
交易额: 73.51万元
企业 |浙江省 |杭州市 |杭州市
交易额: 17.98万元
企业 |河南省 |郑州市 |管城回族区
交易额: 17.14万元
企业 |上海市 |上海市 |黄浦区
成为一品威客服务商,百万订单等您来有奖注册中

价格是多少?怎样找到合适的人才?
¥5000 已有1人投标
¥100000 已有0人投标
¥1000 已有1人投标
¥100 已有0人投标
¥5000 已有1人投标
¥30000 已有0人投标
¥6000 已有0人投标
¥5000 已有3人投标








 企业QQ
企业QQ
 智能客服
智能客服





