 请求处理中...
请求处理中...
请求处理中...
请求处理中...
引言:当手机没网时,AI突然“失灵”了
你是否经历过这样的场景:正在地铁通勤途中,准备用AI助手整理一份重要会议的纪要,信号格却悄然归零,屏幕上方弹出“网络连接失败,请稍后再试”;或者你身处偏远山区,急需查询一份医疗用药禁忌,手机却始终转着圆圈加载不出结果;又或者你是一位对隐私极为敏感的用户,每一次将对话上传云端都让你隐隐不安。
这并非小概率事件。2026年的移动应用行为报告显示,智能手机用户日均处于弱网或无网环境的时长高达47分钟,通勤、差旅、地下空间三大场景贡献了76%的断网诉求。更值得关注的是,在政务、医疗、金融三大强隐私领域,高达63%的用户明确表示“不愿将敏感对话上传云端”。
离线AI不是备胎方案,而是刚需。
然而,当开发者试图将大模型“塞”进手机时,迎面撞上三座大山:1B参数以上的模型动辄2GB,普通App安装包直接超标;iPhone 15 Pro跑Llama 3每秒输出不到10个token,卡顿到用户怀疑人生;更不必说内存溢出导致的闪退、发热引发的降频锁屏。
本文不绕弯子:这是一套从零到一的完整原型方案。你将获得2026年已被验证的技术栈选型清单,一套覆盖模型量化、端侧推理、隐私加密的标准化流水线,以及让对话UI“快过眨眼”的交互设计铁律。如果你的项目正准备启动离线AI开发,这篇指南有望把你的开发周期砍掉60%。
前置准备
在开始操作之前,你需要准备好以下工具和知识储备。
硬件准备:一台用于开发的电脑(建议macOS或Linux环境,16GB以上内存),以及至少一台测试用真机(建议选择市占率较高的中端机型,如Redmi Note系列或iPhone 13,旗舰机测不出性能瓶颈)。
软件准备:Android Studio Ladybug或更高版本、Xcode 16+(仅iOS开发需要)、Flutter SDK 3.20+(如选择跨平台方案)、Java 17(Android部署必需)、Python 3.10+(用于模型转换脚本)。
知识储备:你需要具备基础的移动端开发能力(Android/iOS任选其一),理解命令行操作,并对机器学习中的“量化”“推理”等基础概念有初步认知。
模型准备:在Hugging Face或ModelScope平台上选定一个目标模型。如果你是第一次尝试,强烈推荐Qwen2-0.6B(约600M参数)或Phi-3-mini(约3.8B参数),这两款模型在社区中有最丰富的端侧部署文档,遇到问题时更容易找到解决方案。
核心步骤
步骤一:需求定义与模型选型——先定“体量”,再谈“智能”
所有离线项目的生死线,在选型那一刻就已注定。
核心决策逻辑非常简单:任务复杂度决定参数量,参数量决定机型下限。如果只是做文本分类、意图识别或关键词提取,1B以下模型(如Qwen2-0.5B、Phi-1.6B)完全够用;如果需要流畅对话、摘要生成或轻度推理,1B到3B的模型(如Gemma-2B、Phi-3-mini)是最佳选择;如果追求复杂推理能力,3B到7B的模型(如Llama3-4B、Qwen2-7B)虽然能力更强,但对内存和NPU有硬性要求。
执行这一步骤的关键动作是建立“机型-模型”映射矩阵。以政务智能助手为例,可以将用户设备划分为三档:A类设备(6GB内存以上且支持NPU)部署4B量化模型,B类设备(4GB内存)部署1.5B模型,C类设备(4GB以下)则仅启用基于检索的问答引擎。不要试图用一套模型通吃所有用户,这是离线App最容易犯的战略错误。
工具链方面,Hugging Face模型库支持按参数量筛选,Unsloth则提供了大量现成的量化版本。
步骤二:开发环境与框架选型——跨平台不是可选项
2026年的客观事实是:同时维护iOS和Android两套原生AI栈,中小团队会被拖垮。
推荐架构采用前端Flutter 3.20+,端侧推理引擎采用双引擎策略——iOS优先使用ExecuTorch(Meta出品,对Llama系模型优化极佳),Android以TFLite + XNNPACK为主,低端机型回退至Cactus框架(纯CPU推理,兼容老旧系统)。
这里有一个容易被忽视的避坑提示:ExecuTorch目前对iOS的GPU加速支持优于Android,而TFLite在骁龙平台有更好的Hexagon DSP调用能力。按照平台特性分配引擎,而非强行统一,这是中型团队最高性价比的选择。
环境配置清单包括:Flutter SDK 3.20+、Android Studio Ladybug、Xcode 16+、ExecuTorch 0.3.0、Cactus 0.0.1。
步骤三:模型量化与打包——把“大象”塞进冰箱
这是整个部署流程中最硬核的环节,没有之一。
标准化流程分为三个阶段。首先是精度预选:非实时交互任务(如文档总结)采用INT8量化,体积缩减约50%,精度保留约95%;对话类任务强制使用INT4量化并配合AWQ/GPTQ权重校正,体积压缩约75%,首Token延迟可降低约60%。
第二步是量化感知训练(QAT),如果训练数据可获取,务必做QAT微调。2026年的实践已经证明,后量化模型在长文本生成中更容易出现重复塌陷,而QAT模型在4bit精度下仍能保持连贯的思维链。
第三步是模型分片与懒加载:将3B模型拆分为Embedding层、前20层、后12层三个独立文件。App启动时仅加载前两片,首屏推理速度可提升约2.3倍——这是头部AI应用秘而不宣的优化套路。
最终交付物是一个.pte或.tflite文件,体积不超过1.2GB(针对3B INT4量化模型),放在assets目录或首次启动时流式解压。

步骤四:推理引擎集成——让模型真正“跑起来”
这一步骤的核心是实现模型加载与对话推理的核心代码。以Flutter + ExecuTorch为例,需要异步加载模型并在加载过程中展示进度条。推理时必须采用流式输出,每生成一个token就立即追加到UI上,这种“打字机效果”能极大缓解用户的等待焦虑。
上下文管理是离线AI必须解决的“失忆症”问题。采用SQLite存储对话历史,每条消息记录角色、时间戳和token数。推理时将最近N条消息拼入System Prompt,N值根据机型内存动态计算——4GB机型取5轮,8GB机型可取10轮。
性能基线参考:Redmi Note 12(6GB内存)实测,Gemma 2B INT4量化模型首次加载约11.9秒,平均响应约780ms,功耗比视频播放高约16%。如果低于此指标,说明优化尚未到位。

步骤五:交互原型设计——让“慢”被“快”的感知掩盖
用户无法忍受500ms的空屏等待,但可以接受1000ms的动画加上逐字出现——这是UI心理学的核心红利。
标准化产出物是Figma高保真原型,必须包含三类关键状态。听筒状态可视化需要设计“波形图加光圈呼吸”组件,模型加载时显示“正在思考…”,绝不能只有转菊花。流式文本容器采用StreamBuilder架构,每约40ms刷新一次UI,字体使用无衬线体(SF Pro或PingFang),行高1.6,背景不透明——离线场景没有CDN加速,复杂的毛玻璃效果会直接触发掉帧。离线态感知层需要在状态栏部署弱网或离线标识,但不要频繁弹窗。当用户提问超出本地模型能力时,先回答“我尝试用本地知识库回答”,而非“此问题需联网”——前者是辅助,后者是无能。
工具链方面,Figma配合Anima Playground支持文本转交互原型,非常适合快速验证对话流。
步骤六:测试验证与灰度发布——不要在用户手机上“考古”
三个维度必须覆盖。机型热力图测试重点关注各品牌次旗舰(如小米12、iPhone 13),旗舰机测不出性能瓶颈。内存压力测试需要进行连续50轮对话,用Xcode Instruments或Android Profiler监测内存曲线——合格标准是无持续增长,GC次数少于每分钟5次。真正的离线测试需要开启飞行模式,从冷启动开始全流程走通,特别验证首次启动时模型解压与权限弹窗的并发冲突——这是闪退的重灾区。
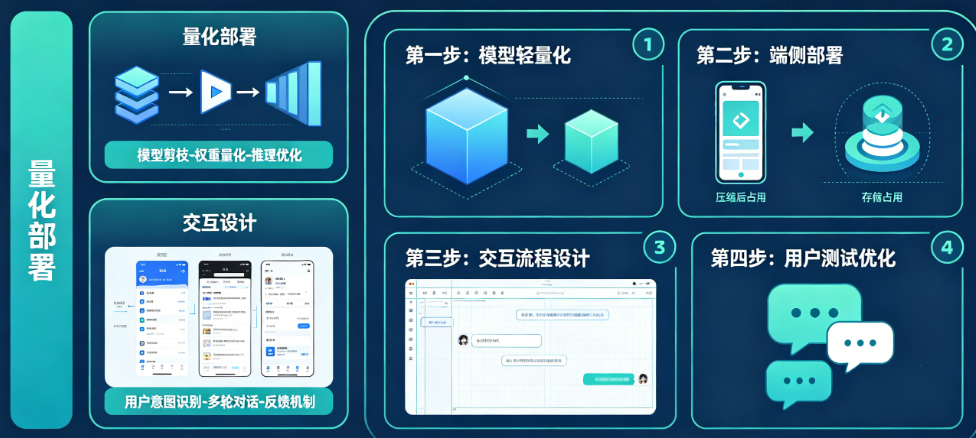
常见问题与避坑指南
误区一:试图用一套模型通吃所有用户。 这是离线App最容易犯的战略错误。正确做法是建立“机型-模型”映射矩阵,甚至为低端机型准备纯检索方案,而非强行推理。
误区二:忽视量化感知训练,只做后量化。 后量化模型在长文本生成中容易重复塌陷,而QAT模型在4bit精度下仍能保持连贯的思维链。如果训练数据可获取,务必做QAT微调。
误区三:加载时不展示进度,让用户傻等。 用户不知道App是在加载还是卡死了。务必展示进度百分比或“正在解压模型”等文字说明,让不确定性转化为确定性。
已经发现的中大型项目在骁龙AI PC或新一代手机平台上运行7B或8B规模的大语言模型没有问题,推理性能表现也很不错。但如果模型规模进一步扩大到13B级别,在移动端运行的难度会显著增加,对内存和带宽的要求也更高——目前建议移动端主要运行7B以下的模型,以兼顾响应速度和能耗控制。
进阶技巧
技巧一:隐私安全感可视化。 离线最大的卖点不是“不用网”,而是“不传数据”。但用户看不到,就不算数。在对话界面顶部增加“端侧处理”常驻徽章,用户删除对话时展示“已从本地安全抹除”动效,设置页加入隐私看板,用图形化方式显示“今日本地处理X条请求”——安全感是需要被设计的。
技巧二:断网状态的体面承接。 用户不会因为断网而愤怒,只会因为App突然变“傻”而愤怒。可以预加载高频问答包:例如政务助手场景,将2000条高频政策问答向量化后随App安装,离线提问直接走本地RAG,无需模型生成,响应快至200ms以内。用户根本意识不到刚才断过网。
技巧三:低功耗视觉动效。 离线AI的电量消耗大头在CPU和GPU,UI动效应尽量减少重绘区域。波形图采用Canvas 2D绘制,避免使用GIF或Lottie复杂动画;文字流式渲染时仅追加新行而非刷新整个ListView;深色模式下降低白色区域面积——每省1mA,都是用户体验。
总结
从模型选型到量化部署,从推理引擎集成到交互原型设计,手机端离线AI对话App的开发是一条完整的技术链路。核心原则只有一条:不要在选型阶段透支后续所有环节——模型体量决定一切,选错了,后面再怎么优化都是徒劳。当你按照本文的六步流程搭建起第一个可运行的原型时,你会发现:离线AI不是“将就”,而是一种更优雅、更私密、更可靠的智能交互方式。
常见问答
Q1:面向离线部署的模型应该选多大参数量的?
A:一个实用的经验法则:1B以下模型适合文本分类、意图识别;1B到3B模型适合对话、摘要;3B到7B模型具备复杂推理能力但需要更高配置。目前主流建议移动端运行7B以下模型,以兼顾响应速度和能耗控制。
Q2:什么是模型量化?INT4和INT8有什么区别?
A:量化就是把模型权重从高精度(如FP32)压缩到低精度整数(如INT8或INT4)。INT8体积缩减约50%,精度保留约95%,适合非实时任务;INT4体积压缩约75%,首Token延迟降低约60%,适合对话类任务。但INT4需要配合AWQ或GPTQ权重校正来保持生成质量。
Q3:用户手机内存不够怎么办?
A:模型分片懒加载是一个有效方案——将模型拆分为多个文件,App启动时只加载必要部分。对于极端低配机型,可以放弃生成式模型,改用基于检索的问答引擎(预先将高频问答向量化存入本地)。
Q4:从PC迁移到手机端需要大量改动吗?
A:如果是通过高通GenieAPIService实现的大语言模型应用,迁移工作量相对较小,主要是把GUI客户端改为基于Android框架的版本。但如果是Python开发的推理逻辑,通常需要将前后处理和界面部分改写为C++或Java实现。
Q5:相比云端API,端侧部署的延迟能降低多少?
A:根据实测数据,端侧NPU运行7B模型单轮响应约100到300毫秒。相比云端API(网络良好时约500到1500毫秒),延迟可降低约60%到80%。网络差时差距更加明显。
如果你正在规划开发一款离线AI对话App,或者需要专业的移动端AI部署服务,一品威客可以为你提供一站式解决方案。 你可以在 【任务大厅】 发布技术开发需求,无论是模型选型咨询、量化部署实施,还是完整App的原型设计与开发,平台汇聚的百万服务商将为你提供专业竞标服务。想要主动寻找有端侧AI落地经验的技术团队?【人才大厅】 里汇聚了涵盖Flutter开发、TFLite/ExecuTorch集成、模型量化等全领域的专业人才,每个服务商都展示了自己的 【商铺】 和过往真实 【案例】 ,信息透明,选择无忧。对于初次接触AI落地的雇主,强烈推荐先去 【雇主攻略】 学习如何写出一份清晰严谨的技术需求书,帮你有效规避项目风险。平台还提供 【一品商城】 ,方便采购正版开发工具授权与素材资源。加入 【V客优享】 ,享受专属客服与任务优先推荐,真正实现“改变你的工作方式”。一品威客以专业的服务生态,助你在端侧AI的浪潮中抢占先机,从原型到产品,一步到位

交易额: 3412.16万元
企业 |山东省 |临沂市 |临沂市
交易额: 1081.25万元
企业 |山东省 |青岛市 |城阳区
交易额: 427.32万元
企业 |山东省 |济南市 |历下区
交易额: 167.8万元
企业 |浙江省 |温州市 |瓯海区
成为一品威客服务商,百万订单等您来有奖注册中

价格是多少?怎样找到合适的人才?
¥3000 已有0人投标
¥1000 已有1人投标
¥100 已有3人投标
¥10000 已有1人投标
¥50000 已有6人投标
¥20000 已有6人投标
¥10000 已有7人投标
¥5000 已有5人投标








 企业QQ
企业QQ
 智能客服
智能客服





