 请求处理中...
请求处理中...
请求处理中...
请求处理中...
开篇:定义问题
“图像分类到底该选CNN、ViT还是MLP-Mixer?”这个问题在计算机视觉领域变得越来越棘手。典型表现非常普遍:你按照某篇热门前沿论文选择了ViT(Vision Transformer),结果在小数据集上训练了三天,准确率还不如一个简单的ResNet;你选了经典的CNN架构,训练速度确实快,但别人用ViT在同样的任务上精度高了两个百分点;你听说MLP-Mixer结构简单、没有注意力机制,结果发现参数量巨大,推理速度反而最慢。更让人头疼的是,不同架构的精度-效率表现随着数据量和任务类型剧烈变化,网上评测结果往往自相矛盾,有的说ViT效率高,有的说CNN仍然最强,让你完全不知道该信谁。
导致这个问题的根本原因有三点。第一,很多人对这三种架构的本质缺乏理解——CNN依赖局部卷积归纳偏置,在小数据上天然高效;ViT完全靠注意力机制学习全局关系,需要大量数据才能发挥优势;MLP-Mixer用全连接层混合空间和通道信息,理论上最简单但实际计算量惊人。第二,精度和效率的权衡往往被割裂看待,有人只看最高精度忽略训练成本,有人只图快不顾模型能力上限,导致选型严重偏科。第三,缺乏一套基于实际约束条件(数据量、推理延迟要求、显存限制)的量化决策框架,只能靠道听途说或者盲目跟风顶会论文选架构。
主体:完整解决方案
核心理念原则
解决架构选型问题,必须遵循三条最高原则。原则一:归纳偏置强度与数据量匹配——架构自带的先验越强,在小数据上表现越好,但可能限制大数据的上限。原则二:效率必须按场景定义——训练效率看收敛速度,推理效率看延迟和吞吐量,移动端和云端完全是两套标准。原则三:精度收益的边际递减规律——从80%提到85%很容易,从95%提到96%可能让模型体积翻倍,必须根据业务阈值决定是否值得。
工具准备
CNN家族推荐ResNet、EfficientNet和ConvNeXt,前两者久经考验,后者是现代化的CNN设计。ViT推荐原生ViT、DeiT(数据高效的ViT)和Swin Transformer(分层ViT)。MLP-Mixer推荐原始MLP-Mixer和ResMLP,后者针对推理优化。所有架构均有PyTorch和TensorFlow的官方或社区实现,免费使用,需要GPU训练。
标准化解决流程
准备阶段:先明确三个约束条件——你的训练数据有多少张图片?每个类别样本是否均衡?推理场景要求多少毫秒内返回结果?运行设备是云端GPU、边缘盒子还是手机?
执行阶段按照三条精度-效率曲线做出选择。
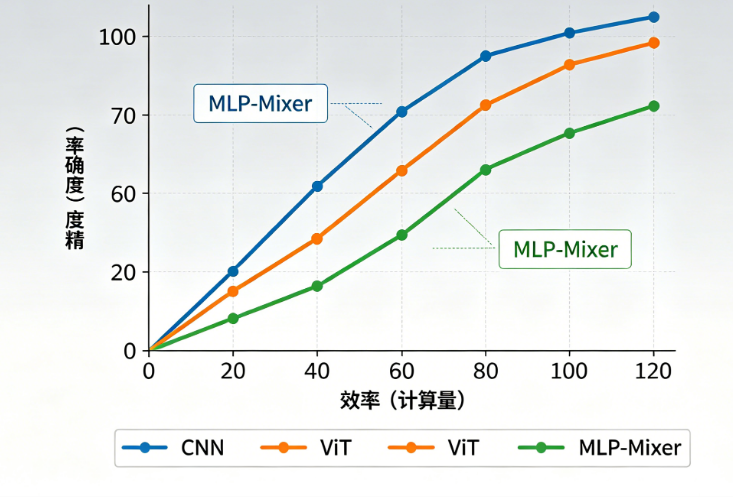
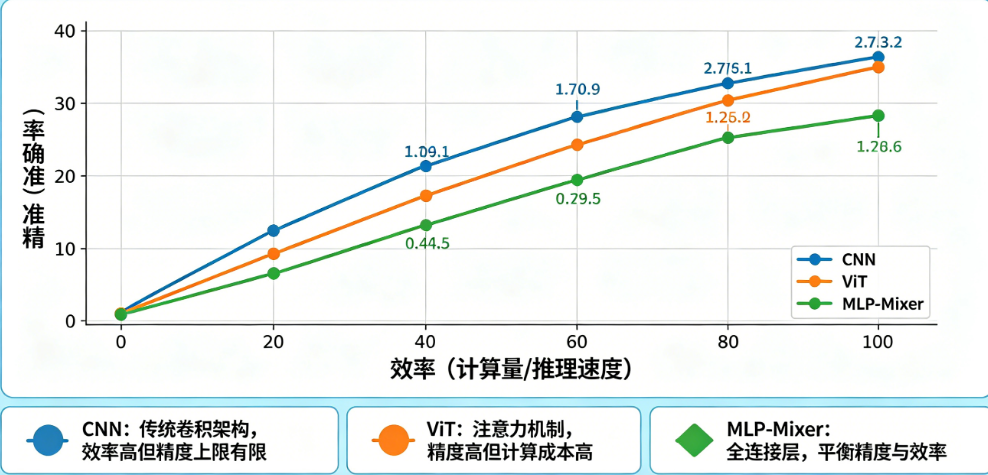
曲线一:小数据场景(每个类别少于500张图片)。CNN是唯一合理的选择。因为CNN的卷积操作天然假设“局部邻近像素相关性强”,这种归纳偏置在小数据时相当于免费的正则化。具体推荐:EfficientNet-B0到B3级别,参数量5M到10M,使用ImageNet预训练权重微调。ViT在此场景下表现糟糕——注意力机制需要大量数据才能学到有意义的全局关系,强行使用会导致严重的过拟合。MLP-Mixer同样不推荐,它没有空间局部性假设,全连接层的参数量爆炸式增长,小数据下几乎无法训练。当你看到别人用ViT在小数据集上跑出好结果时,那大概率是因为他们用了大规模的蒸馏或数据增强技巧,普通开发者不应照搬。
曲线二:中等数据场景(每个类别500到5000张图片,总数据量5万到50万)。这是分水岭区域,CNN和ViT都能工作,但取舍不同。如果你的首要目标是训练速度和推理延迟,选CNN——EfficientNet或ConvNeXt可以在保持高精度的同时,做到ViT的三分之一推理时间。如果你的首要目标是冲击最高精度,且不在乎训练时间多花2到3倍,选ViT——但注意必须使用DeiT的训练策略(强数据增强+知识蒸馏),否则精度可能不如CNN。MLP-Mixer在这个区间仍然不推荐,它的参数量是CNN的5到10倍,精度却通常低于同等算力的ViT。
曲线三:大数据场景(总数据量超过50万,甚至百万级)。ViT开始真正展现优势。当数据足够多时,ViT可以从零学到比卷积更优的归纳偏置,精度上限超过最好的CNN。典型的例子是JFT-300M上训练的ViT迁移到ImageNet后刷新纪录。但这里有一个关键陷阱:如果你没有大规模预训练的条件,只能使用公开的ImageNet-21k或JFT预训练权重,那么CNN和ViT的精度差距其实很小,而CNN的推理效率仍然遥遥领先。所以除非你有能力自己训练大数据集,否则不要盲目追求ViT。至于MLP-Mixer,它在大数据上的精度上限介于CNN和ViT之间,但参数量和计算量是三者中最高的,几乎没有场景值得选择。
进阶优化优化方案
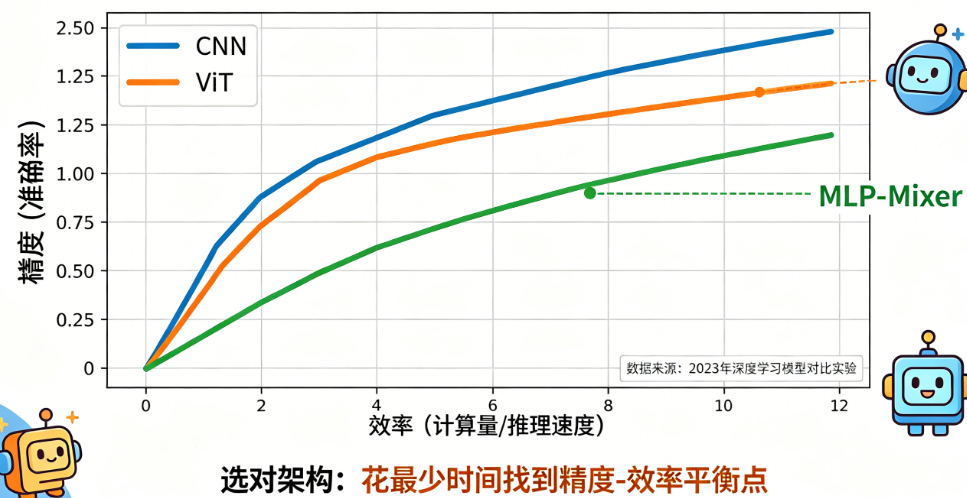
如果你追求极致效率,可以考虑混合架构:前几层用CNN快速提取局部特征,后几层用ViT做全局关系建模,典型代表是ConvNeXt的现代CNN设计或CoAtNet。这种方案在中等数据上通常比纯ViT收敛更快、数据效率更高。另一个方向是使用架构搜索或动态剪枝——对于CNN和ViT,训练后剪枝可以去掉30%到50%的参数量,精度损失控制在1%以内,推理速度翻倍。
常见问答
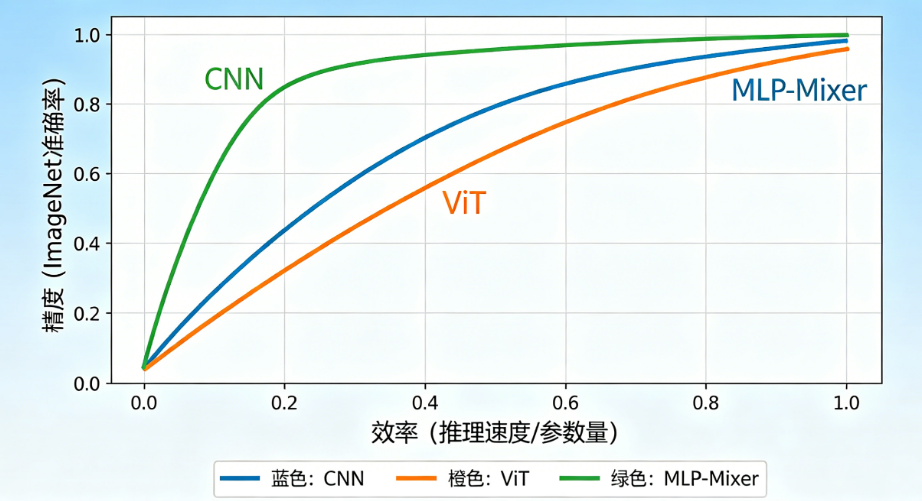
问:ViT是不是一定比CNN更好?答:不是。只有在大数据和充足预训练的条件下,ViT的精度上限才超过CNN。在绝大多数工程场景中,CNN仍然是精度-效率平衡最好的选择。
问:MLP-Mixer到底有没有用?答:学术上有启发意义,证明全连接层也能做视觉任务。但实际工程中几乎没有优势——精度不如ViT,效率不如CNN,不推荐使用。
问:我不想折腾,就想选一个通用的,选哪个?答:ConvNeXt或EfficientNet V2。这是现代CNN的巅峰,精度接近ViT,效率远超ViT,数据效率高,调参简单,几乎不会踩坑。
操作后的改善效果
按照本文的精度-效率曲线选型后,你将在项目启动第一天就锁定最优架构,避免“训练三天发现不行再换”的巨大时间浪费。根据实际经验,正确选型能让模型开发周期缩短50%以上——因为你不再需要在三个架构之间反复试错。
自查清单
是否统计了训练集总样本数和每个类别的样本数? 是否明确了推理延迟要求(毫秒级/实时/离线批量)?是否确认了可用的GPU显存和训练时间预算?是否评估了使用预训练权重的可能性?是否理解了业务对精度的阈值要求(是否值得为最后1%精度付出3倍代价)?
一品威客任务大厅每天都有大量计算机视觉项目需求发布,从工业缺陷检测、安防监控识别到医疗影像分析,应用场景丰富。如果你正在为图像分类项目的架构选型发愁,不妨在任务大厅发布你的具体需求,详细描述数据量、精度目标和部署环境,平台会快速为你匹配合适的算法工程师。你也可以在人才大厅按技能标签搜索“CNN”“ViT”“图像分类”等关键词,查看服务商的过往案例作品和客户评价,选择在特定架构上有实战经验的人选。想了解类似项目的成功做法,可以进入服务大厅浏览各类商铺案例,看看别人是如何平衡精度与效率、完成从模型选型到上线的全流程。别忘了收藏威客攻略栏目学习选型方法论和调优技巧,开通V客优享会员更能享受优先推荐和专属客服,真正改变你的工作方式。一品威客汇聚百万服务商提供从算法设计到系统集成的完整技术服务,你还可以通过一品威客网热门标签频道,如“深度学习”“视觉算法”“模型压缩”等热门搜索词,快速定位优质服务商,享受高效、透明、专业的一站式网站体验,让你的视觉项目从一开始就走对方向。


价格是多少?怎样找到合适的人才?
¥3000 已有0人投标
¥1000 已有0人投标
¥10000 已有3人投标
¥1000 已有13人投标
¥20000 已有0人投标
¥50000 已有0人投标
¥3000 已有0人投标
¥100000 已有0人投标








 企业QQ
企业QQ
 智能客服
智能客服





