 请求处理中...
请求处理中...
请求处理中...
请求处理中...
开篇:定义问题
“分类任务该选XGBoost还是神经网络?”这是许多数据科学新手甚至中级从业者经常陷入的困境。这个问题的典型表现非常具体:训练出的模型准确率始终上不去;换了好几个算法效果都差不多;模型在小数据集上过拟合严重,换个数据集又欠拟合;或者模型训练时间长得离谱,调整参数耗费数周仍无起色。更令人头疼的是,同样的算法在不同项目上表现天差地别,让人完全摸不着规律。
导致这个问题的根本原因主要有三个。第一,很多人不重视“数据量”这个最基础的变量,总觉得算法越高级效果越好,却不知道神经网络恰恰需要海量数据才能发挥优势。第二,对工具的本质理解不够——XGBoost是基于决策树的集成模型,擅长处理表格数据和复杂特征交互,而神经网络是通用函数逼近器,需要大量数据来学习参数。第三,缺乏一套清晰的选型方法论,总是在试错中浪费时间。本文将彻底解决这一问题,按照数据量三个档位给出明确指引。
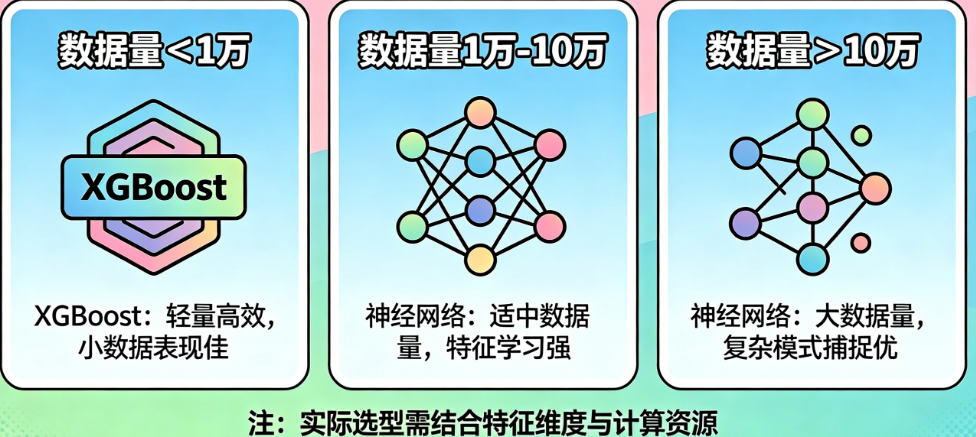
主体:完整解决方案
核心理念原则
解决分类模型选型问题,必须遵循三条最高原则。原则一:数据量优先于模型复杂度——没有足够的数据,复杂模型只会过拟合。原则二:表格数据优先选树模型,非结构化数据优先选神经网络——这来自于两种模型本质的归纳偏置差异。原则三:先快速验证基线,再优化迭代——不要在错误的模型上浪费时间调参。
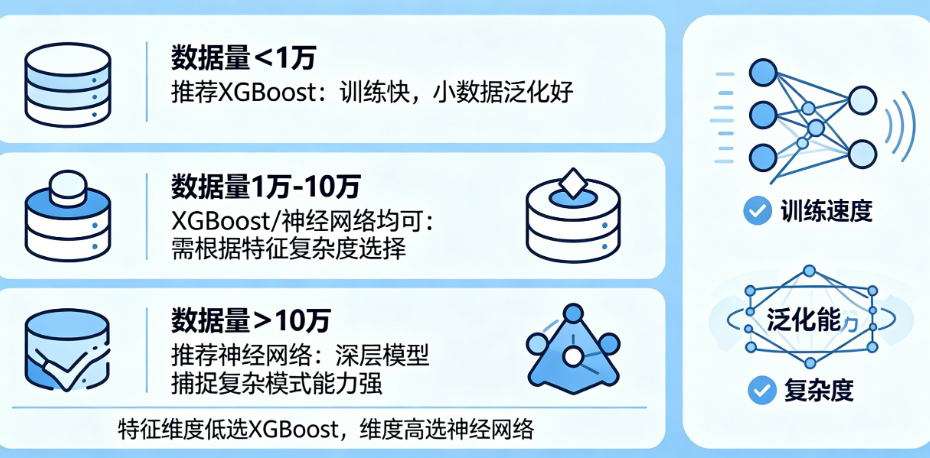
工具准备
XGBoost方面,推荐使用原生XGBoost库(免费,支持Python、R、Java等),LightGBM和CatBoost作为补充选项。神经网络方面,推荐PyTorch或TensorFlow(免费,Python生态),对于完全新手,也可使用Keras简化操作。所有工具均跨平台,电脑端运行,无需手机端工具。
标准化解决流程
准备阶段:首先明确你的数据量到底是多少条样本?统计每个类别的样本数是否均衡?特征是什么类型(数值型、类别型、文本型、图像型)?目标是什么(二分类、多分类)?执行阶段严格按照以下三档选择。
第一档:数据量小于1万条。毫不犹豫选择XGBoost。理由很简单:神经网络在此数据量下极易过拟合,即使使用Dropout、正则化也很难稳定;而XGBoost的树模型天然具有正则化结构,对噪声不敏感。具体操作:先用默认参数训练一个基线模型,一般就能达到不错效果。然后重点关注树的数量(n_estimators)设为300-500,最大深度(max_depth)设为3-6,学习率(learning_rate)设为0.05-0.1,加上早停机制。如果特征是高度稀疏或类别特征多,可换用CatBoost。不要在这个档位尝试任何深层神经网络。
第二档:数据量在1万到10万之间。这是灰色地带,需要根据具体特征类型判断。如果你的特征是表格型(数值+类别),且特征工程后维度在几十到几百之间,XGBoost仍然是更稳妥的选择,训练速度快、可解释性强、调参简单。但如果你处理的是文本、时序信号、频谱图等非结构化数据,可以考虑浅层神经网络(1-2个隐藏层,每层64-256个神经元)。具体操作:先跑XGBoost基线,如果效果明显不满足需求,再用小型MLP做对比。这一档位下,两种模型都可以工作,但XGBoost更省心,神经网络需要更多调参技巧(学习率调度、批量归一化、早停等)。
第三档:数据量大于10万条。此时神经网络可以开始展现优势,但前提是你的计算资源足够。具体操作:首先,如果特征维度很高(如词袋模型上万的维度),XGBoost会变得很慢,而神经网络可以高效处理。其次,如果你拥有GPU,神经网络训练时间会随数据量线性增长,而XGBoost在CPU上会显著变慢。最后,对于图像、语音、文本等深度学习擅长的领域,数据量超过10万后,预训练模型微调的效果往往远超XGBoost。但注意:如果仍是非常规整的表格数据,且类别特征不多,XGBoost和LightGBM在百万级数据上依然表现优异,甚至优于神经网络。
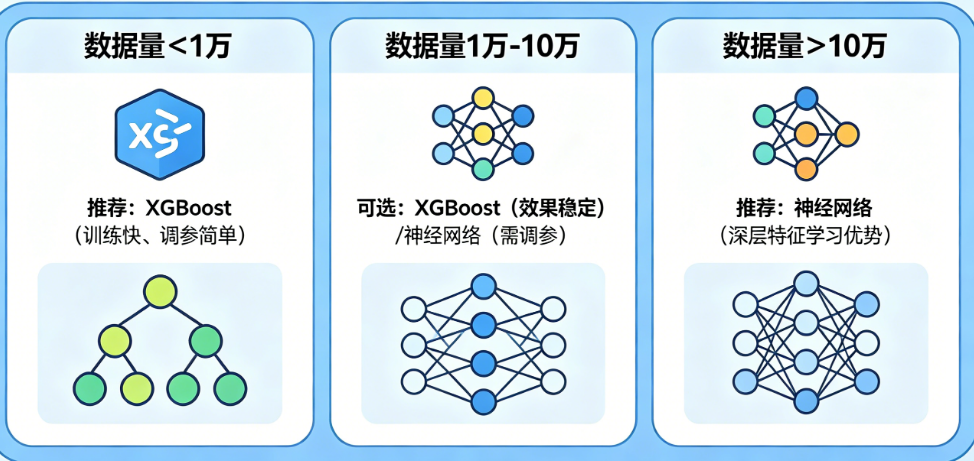
进阶优化方案
对于小于1万的数据,使用带先验的贝叶斯方法或在XGBoost中加入类别特征的目标编码。对于1万到10万的数据,尝试XGBoost+逻辑回归的Stacking融合,或者用神经网络对XGBoost的残差进行修正。对于大于10万的数据,使用迁移学习(特别是图像文本任务)或分布式训练框架,并将模型切换到CatBoost处理极多类别特征。
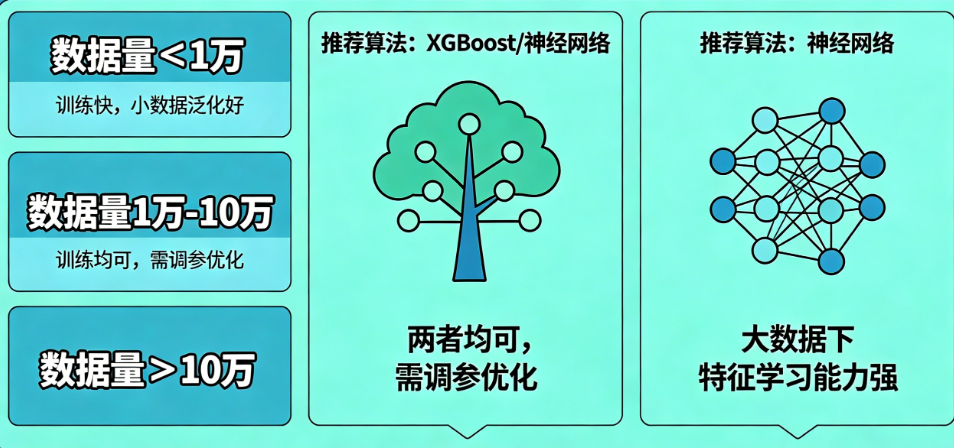
常见问答
问:数据量小于1万,但用了神经网络效果也很好是怎么回事?答:可能是因为特征非常规则(如人造数据)或任务极其简单,但真实业务场景中这属于例外,不应作为常规选型依据。
问:XGBoost和LightGBM选哪个?答:数据量小于5万用XGBoost,超过5万用LightGBM,后者速度更快、内存更省。
问:有没有可能先少量数据用XGBoost,数据多了再切神经网络?答:完全可行,但注意特征工程口径要统一,且神经网络需要重新从头训练。
操作后的改善效果
按照本文方法操作后,你将彻底告别选型迷茫——第一次训练就能获得合理基线,调参时间从数周缩短到半天,模型过拟合和欠拟合问题显著减少。更重要的是,你将形成一套基于数据量的决策框架,后续每个分类项目都能快速锁定正确工具。
自查清单
是否准确统计了训练集的样本总数?是否确认了特征类型(表格/非结构化)? 是否根据数据量三档选择了主模型?是否在选型前先跑了一个简单基线? 是否评估了计算资源(CPU/GPU)和时间预算?
如果你正在寻找专业的数据科学服务,不妨上一品威客任务大厅发布你的分类建模任务需求,快速匹配经验丰富的数据算法工程师。你也可以在人才大厅按技能标签搜索“XGBoost”或“神经网络”,查看人才的作品案例与用户评价。想了解如何更好管理数据项目,可进入服务大厅浏览商铺案例,看看同行如何从数据清洗到模型部署一气呵成。别忘了收藏威客攻略学习实用技巧,开通V客优享会员更能解锁优先推荐权益,改变你的工作方式。一品威客汇聚百万服务商提供文化创意与技术开发服务,你还可以通过一品威客网热门标签频道,如“机器学习”“数据挖掘”“Python建模”等关键词,快速定位优质服务商,享受高效、靠谱的网站体验。


价格是多少?怎样找到合适的人才?
¥3000 已有0人投标
¥1000 已有0人投标
¥20000 已有0人投标
¥5000 已有2人投标
¥10000 已有1人投标
¥100 已有8人投标
¥1000 已有0人投标
¥5000 已有1人投标








 企业QQ
企业QQ
 智能客服
智能客服





