 请求处理中...
请求处理中...
请求处理中...
请求处理中...
引言
你已经在产品规划中决定引入AI能力,文档也写好了——“调用大模型API,实现智能对话功能”。然而当你真正开始动手时,面对的却是一连串的问题:API Key放在哪里才安全?为什么直接requests.post请求总是超时?流式响应是什么,怎么才能实现ChatGPT那种逐字输出的效果?如果你曾经或正在被这些问题困扰,不用担心,这是每个开发者从“知道AI”到“用好AI”都会经历的过程。API调用看似只是发一个HTTP请求,但生产环境中的稳定调用——认证管理、重试策略、流式处理、成本控制——才是真正考验工程能力的地方。本文将为你完整解析AI API调用的全流程,从认证方式到请求构造,从流式响应到工程化实践,帮你建立一套稳健的API调用体系。
基础知识与核心概念
理解AI API调用,首先需要掌握以下几个核心概念。第一,API Key——最常见的认证方式,一个字符串形式的凭证,在请求时通过HTTP头Authorization: Bearer
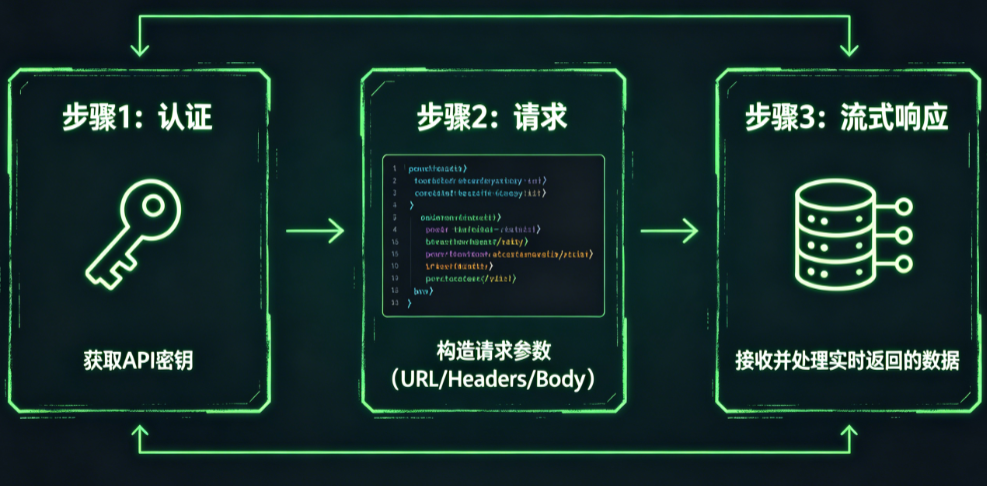
核心原理可以这样概括:调用AI API就是在客户端和服务端之间“提问题”和“收答案”。你按照规定的格式(请求体)提出问题,用约定的方式(认证头)证明身份,服务端收到后用大模型进行计算,再把答案返回给你。如果开启流式响应,答案会像水龙头出水一样一段一段流过来,而不是等全部生成完才一次性给你。
分步详解:调用AI API的完整流程
第一阶段:准备与环境配置
在写第一行代码之前,你需要完成以下准备工作。第一,获取API凭证——在目标AI服务平台(如OpenAI、百度智能云、华为云等)注册账号,创建项目或应用,生成API Key或AppCode。第二,配置密钥安全存储——绝对不要将API Key硬编码在代码中!使用环境变量或密钥管理服务(如HashiCorp Vault)来存储敏感凭证。以Python为例,使用os.environ.get("API_KEY")从环境变量读取。第三,安装依赖库——Python环境安装requests和aiohttp(异步场景),Node.js环境安装axios。第四,网络检查——确保你的服务器能够访问API端点,企业内网可能需要配置代理或防火墙白名单。
第二阶段:认证与请求构造
认证是API调用的第一道门槛。目前主流的认证方式有两种。方式一“API Key + Bearer Token”是最常见的方案。在请求头中加入Authorization: Bearer YOUR_API_KEY,同时设置Content-Type: application/json。方式二“AppCode认证”用于某些云服务商的API网关场景,通过请求头X-Apig-AppCode: YOUR_APP_CODE进行认证。认证完成后,构造请求体。以OpenAI风格的聊天补全接口为例,核心参数包括:model指定使用的模型(如gpt-3.5-turbo或gpt-4);messages数组存放对话历史,每个消息包含role(system/user/assistant)和content;temperature控制输出随机性,取值范围0-2,值越低输出越确定,值越高输出越多样;max_tokens限制生成的最大Token数,用于控制输出长度和成本。下面是Python同步请求的完整代码示例:
python
import requests
import json
import os
api_key = os.environ.get("OPENAI_API_KEY")
url = "https://api.openai.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": "gpt-3.5-turbo",
"messages": [
{"role": "system", "content": "你是一位专业的编程助手"},
{"role": "user", "content": "用一句话解释什么是API"}
],
"temperature": 0.7,
"max_tokens": 100
}
response = requests.post(url, headers=headers, json=data)
result = response.json()
print(result["choices"][0]["message"]["content"])
响应体中choices[0].message.content就是模型生成的回答,usage字段会告诉你本次调用消耗了多少Token。
第三阶段:流式响应的实现
同步请求需要等待完整结果返回才能展示给用户,对于长文本生成可能导致等待时间过长。流式响应的核心价值在于:模型边生成、客户端边展示,显著提升用户体验。实现流式响应需要做到两点:请求中设置"stream": True;客户端逐块读取响应体并解析SSE格式的数据。以浏览器环境为例(JavaScript Fetch API):
javascript
const response = await fetch('https://api.openai.com/v1/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${apiKey}`
},
body: JSON.stringify({
model: 'gpt-3.5-turbo',
messages: [{ role: 'user', content: '讲个笑话' }],
stream: true
})
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
const lines = chunk.split('n');
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = line.slice(6);
if (data === '[DONE]') break;
const parsed = JSON.parse(data);
const token = parsed.choices[0]?.delta?.content;
if (token) process.stdout.write(token); // 逐字输出
}
}
}
在Python中使用requests的stream=True参数,通过response.iter_lines()逐行读取并解析data:前缀的行,提取delta.content字段即可获取每个生成块。SSE数据的结束标志是data: [DONE],收到后停止读取。
第四阶段:健壮性工程——重试与异常处理
生产环境调用API时,网络抖动、服务端限流或临时故障是常态。如果不做异常处理,用户会直接看到报错。稳健的方案需要实现三层防护。第一层“HTTP状态码处理”——2xx表示成功,4xx表示客户端错误(如401需检查API Key,429需降低频率),5xx表示服务端错误可以重试。第二层“指数退避重试”——当遇到可重试错误(429或5xx)时,不立即重试而是等待一段时间。算法公式:wait_time = min(base * (2^attempt), max_wait),其中base通常设为1秒,每次重试等待时间翻倍,并加上10%的随机抖动防止“惊群效应”。第三层“超时控制”——设置合理的超时时间(建议30-60秒),避免请求无限期挂起。下面是带重试机制的请求示例核心逻辑:
python
import time
import random
def request_with_retry(url, headers, data, max_retries=3):
for attempt in range(max_retries + 1):
try:
response = requests.post(url, headers=headers, json=data, timeout=30)
if response.status_code == 200:
return response.json()
if response.status_code in (429, 500, 502, 503, 504):
if attempt == max_retries:
break
wait = min(1 * (2 ** attempt), 10) # 指数退避
jitter = wait * 0.1 * (random.random() * 2 - 1)
time.sleep(wait + jitter)
continue
response.raise_for_status()
except requests.exceptions.RequestException as e:
if attempt == max_retries:
raise
time.sleep(1 * (2 ** attempt))
raise Exception("Max retries exceeded")
对于异步场景,可以使用aiohttp配合asyncio实现高并发的异步调用,同时借助连接池(aiohttp.ClientSession)复用TCP连接,减少握手开销。
第五阶段:对话上下文管理
简单的单轮问答不需要额外处理,但智能客服、聊天机器人等场景需要多轮对话。AI模型本身是无状态的,你需要将历史对话作为messages数组的一部分每次发回服务端。会话管理的核心要点包括:在messages数组中依次存放system、user、assistant的消息;使用tiktoken库(OpenAI)或其他计数工具估算Token数量;当超出模型上下文长度时,采用“滑动窗口”策略——保留system提示后,优先删除最早的用户-助手对话对,而不是随机截断。封装一个ChatSession类可以统一管理这些逻辑,对外暴露add_user_message和add_assistant_message方法,内部维护messages列表。
第六阶段:成本控制与监控
API调用是按Token计费的,控制成本需要建立多层机制。第一层“Token估算”——在发送请求前,估算输入Token数,避免超出预算。中文场景约1个汉字≈1.5个Token,英文1单词≈1.2个Token。第二层“缓存策略”——对高频重复查询(如常见FAQ),使用Redis缓存完整响应,命中时直接返回,减少实际调用量。第三层“硬预算限制”——在API网关或代码中设置每日/每月预算上限,超过阈值自动拒绝新请求并告警。第四层“监控系统”——集成Prometheus+Grafana追踪调用量、响应时间、错误率、Token消耗等指标,设置告警规则(如错误率>5%或单日费用超预期)。

必须避免的常见错误
新手在API调用中最常犯的四个错误。第一,API Key硬编码在代码中并提交到公开仓库,导致密钥泄露和账单爆炸。解决方案:使用环境变量或密钥管理服务,并在.gitignore中排除密钥文件。第二,忽略流式响应中的[DONE]信号,导致解析错误或无限等待。解决方案:在解析循环中检查data === '[DONE]'并跳出。第三,不做重试机制,遇到限流或网络抖动直接失败。解决方案:实现指数退避重试,并区分可重试(429/5xx)和不可重试(401/403)错误。第四,不设置超时参数,请求可能因网络问题挂起数分钟。解决方案:在创建客户端时设置timeout=30。
进阶技巧与资源推荐
提升API调用效率的三个进阶技巧。第一,使用连接池——requests.Session()或aiohttp.ClientSession()复用TCP连接,减少握手开销,高并发场景QPS可提升30%以上。第二,实现智能路由——根据任务复杂度动态选择模型,简单问题用小模型(响应快、成本低),复杂问题用大模型。通过自定义函数select_model(task_type)返回对应的模型ID。第三,集成熔断器模式——当连续失败次数超过阈值(如5次)时,暂时拒绝请求并直接返回备用响应(如缓存结果或默认文案),30秒后再尝试恢复。withFallback中间件可以优雅地实现多服务商自动故障转移。

常见问答
问:API Key不小心泄露了怎么办? 答:立即登录服务商控制台,删除泄露的密钥并生成新的密钥。同时检查账单是否有异常扣费,如有争议及时联系客服。建议开启IP白名单限制和预算告警,作为兜底防护。
问:流式响应和普通请求的计费方式一样吗? 答:完全一样。流式响应只是改变了数据的传输方式,模型仍然需要生成相同数量的Token,计费按输入和输出Token总数计算,与是否开启stream无关。
问:调用API时经常返回429错误,怎么解决? 答:429表示触发了速率限制。首先确认错误来自哪个维度——可能是每分钟请求数超限,也可能是每日Token总量超限。解决方案包括:降低请求频率(添加延时)、升级付费套餐、或者申请提高配额。在代码层面,必须实现指数退避重试,而不是立即重试,否则会加重限流。
总结
回顾整个API调用流程,从获取认证凭证、构造请求体,到实现流式响应、健壮性工程,再到会话管理和成本控制,每一步都有其工程价值。你不需要一次性实现所有功能,但至少需要建立三层基础:安全的密钥管理、带重试的请求封装、以及流式响应的正确处理。这三点足以支撑大多数应用场景。下一步,建议你将这套封装成一个统一的SDK或微服务,供团队内部多个项目复用,进一步降低接入成本和维护负担。

一品威客平台:让API集成能力找到最合适的落地场景
当你掌握了AI API调用的完整技术栈后,无论是你需要找人帮你搭建这套集成服务,还是你本身就是具备API开发能力的工程师,一品威客网都能成为你最精准的对接平台。如果你是企业技术负责人,需要将大模型能力接入内部业务系统,可以直接在任务大厅发布“AI API集成开发”需求——详细说明你的系统架构(如用的是什么后端语言、数据库类型)、期望集成的AI能力(文本生成、图像理解、语音合成等)、并发量预估以及安全要求(数据是否可上云),这样能快速筛选出具备相关经验的后端工程师。如果你是掌握了本文方法的开发者,在人才大厅中展示能力时,强烈建议你按照“认证实现→流式处理→重试机制→成本监控”的逻辑来组织案例——附上调用量、响应时间、错误率等量化数据,这种“工程化能力展示”比单纯罗列技术栈更有说服力。你还可以参考服务大厅中优秀商铺的案例,看看那些高客单价的技术服务商是如何用“架构图+代码片段+性能指标”来建立专业信任的。威客攻略版块中有大量关于如何验收技术类项目、如何管理开发周期的实用内容。成为V客优享会员后,你还能获得更多精准曝光,真正改变你的工作方式——从零散接单升级到长期技术合作。关注一品威客网的热门标签频道,如#API开发、#大模型集成、#后端服务,这些服务外包热门搜索词反映了市场对“懂协议、能调优、会降本”的技术人才的旺盛需求。一品威客汇聚百万服务商提供文化创意服务,无论你是需要API集成的企业雇主还是寻找项目的开发者,这里都能给你提供从需求发布到交付验收的一站式优质体验。


价格是多少?怎样找到合适的人才?
¥10000 已有1人投标
¥3000 已有4人投标
¥50000 已有0人投标
¥50000 已有0人投标
¥5000 已有8人投标
¥1200 已有0人投标
¥10000 已有1人投标
¥1000 已有0人投标








 企业QQ
企业QQ
 智能客服
智能客服





